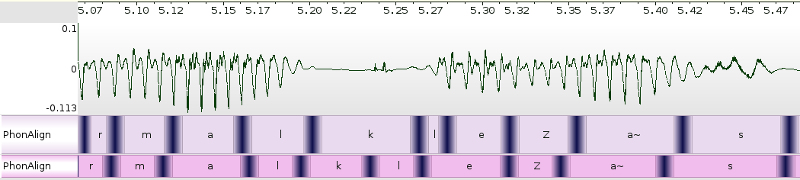
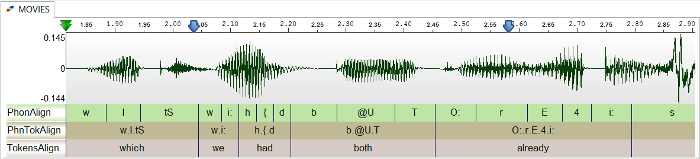
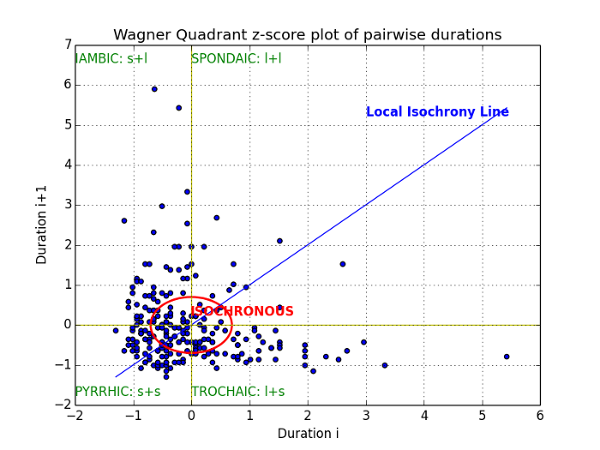
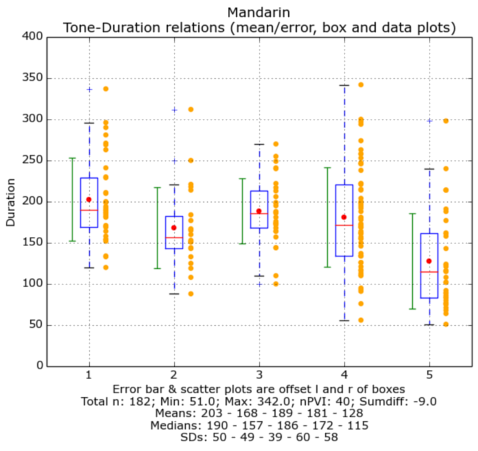
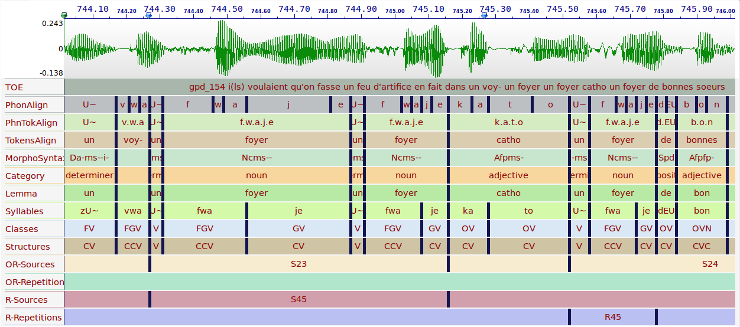
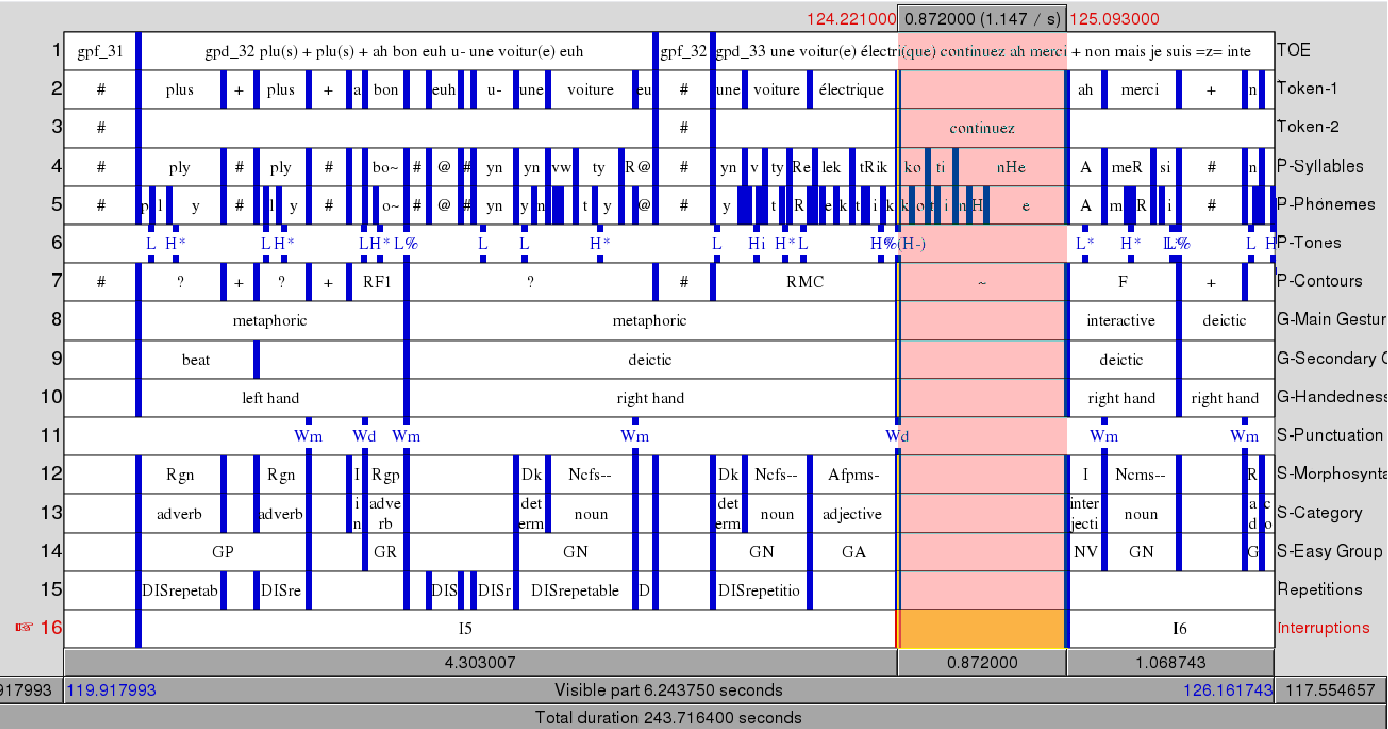
Corpus annotation: Manual vs. Automatic
- The wide range of annotations, from aligned transcripts to gaze to reference to gestural form, is costly to collect and to annotate, both in terms of time and money.
- Each annotation that can be done automatically must be done automatically!
- Why? Because revising is faster and easier than annotating... if the automatic system is "good enough".