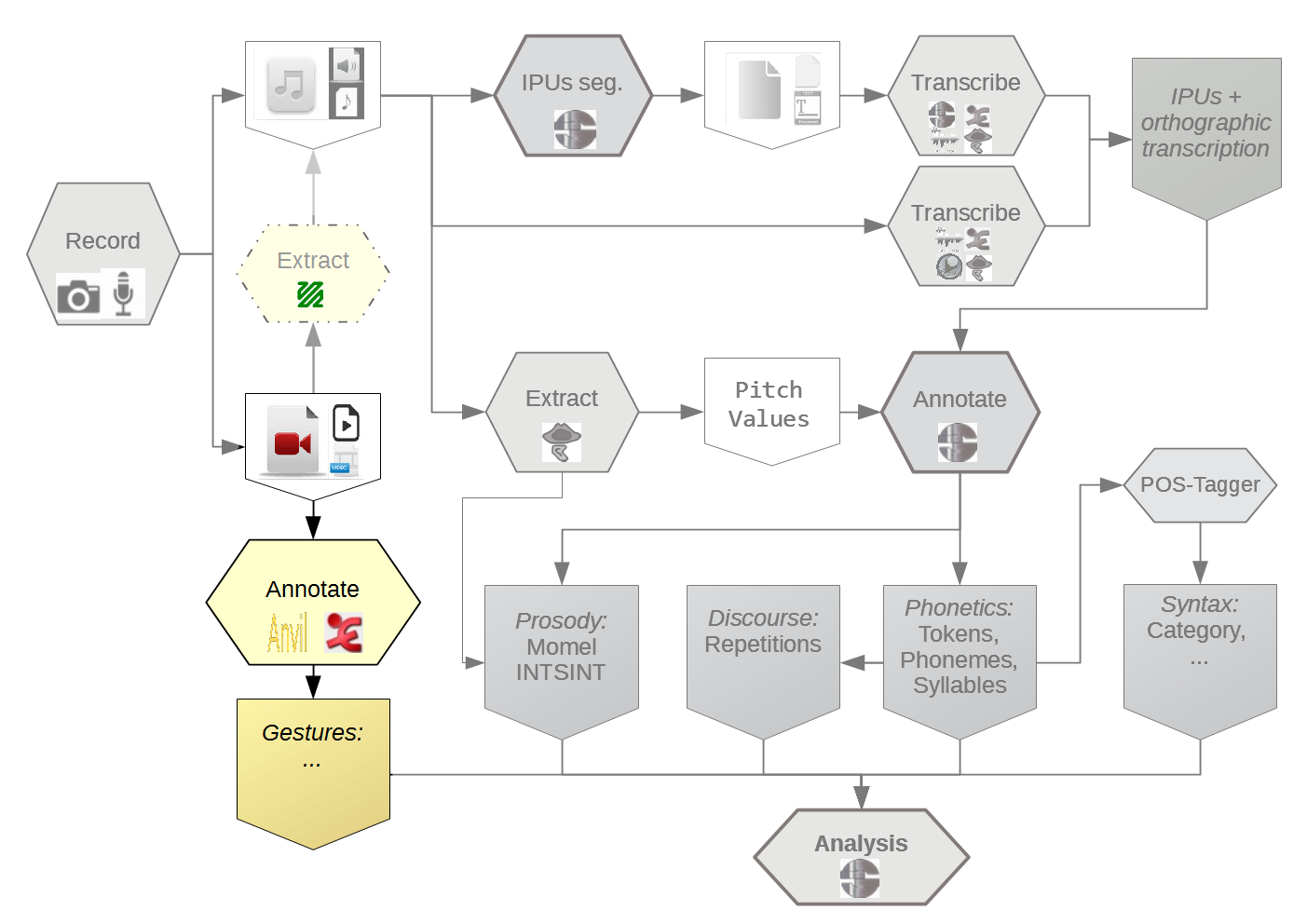
Limitation
-
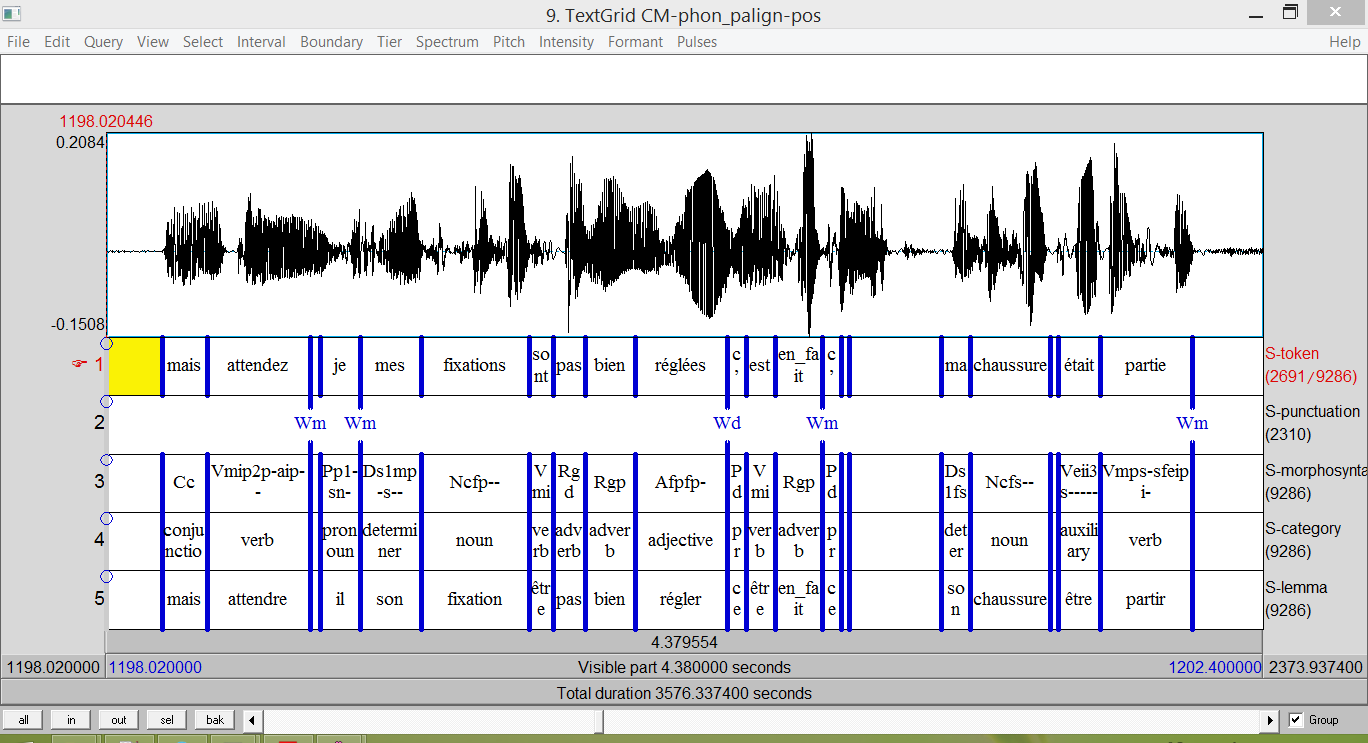
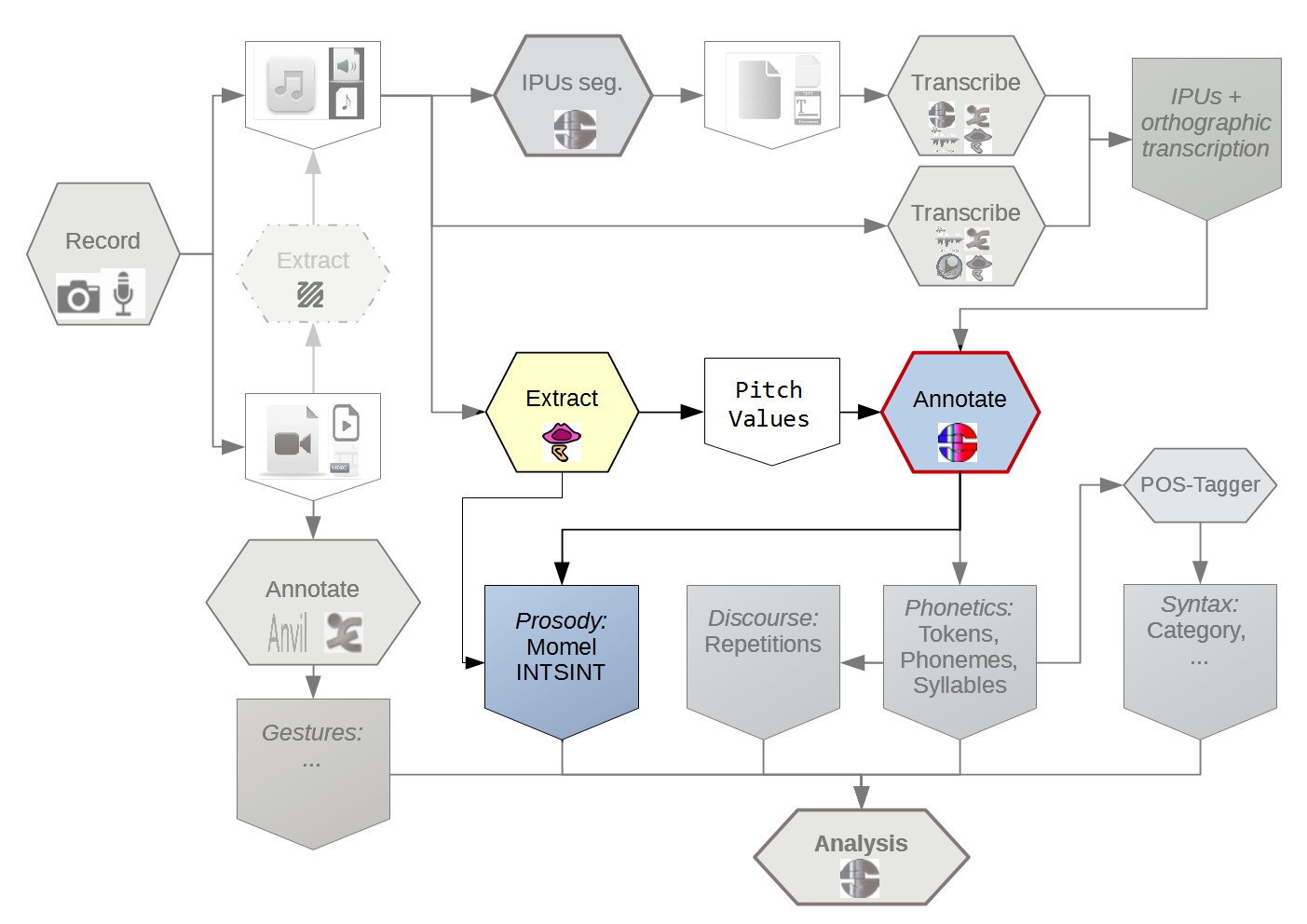
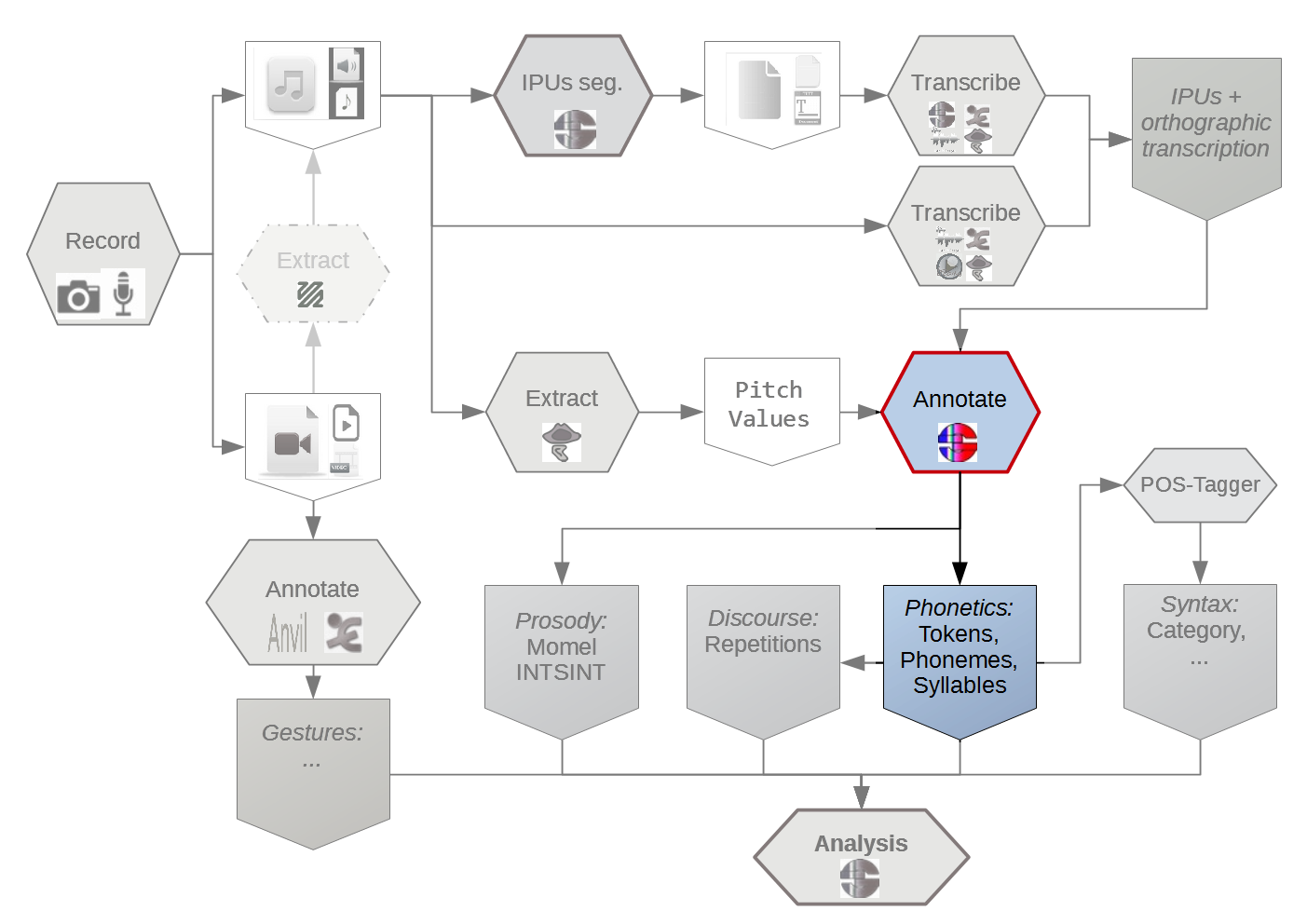
The scope of the proposed workflow is broad and, therefore, complete coverage is challenging.
-
It is very unrealistic to consider that human analyst can be removed from the process of annotation.

The scope of the proposed workflow is broad and, therefore, complete coverage is challenging.
It is very unrealistic to consider that human analyst can be removed from the process of annotation.
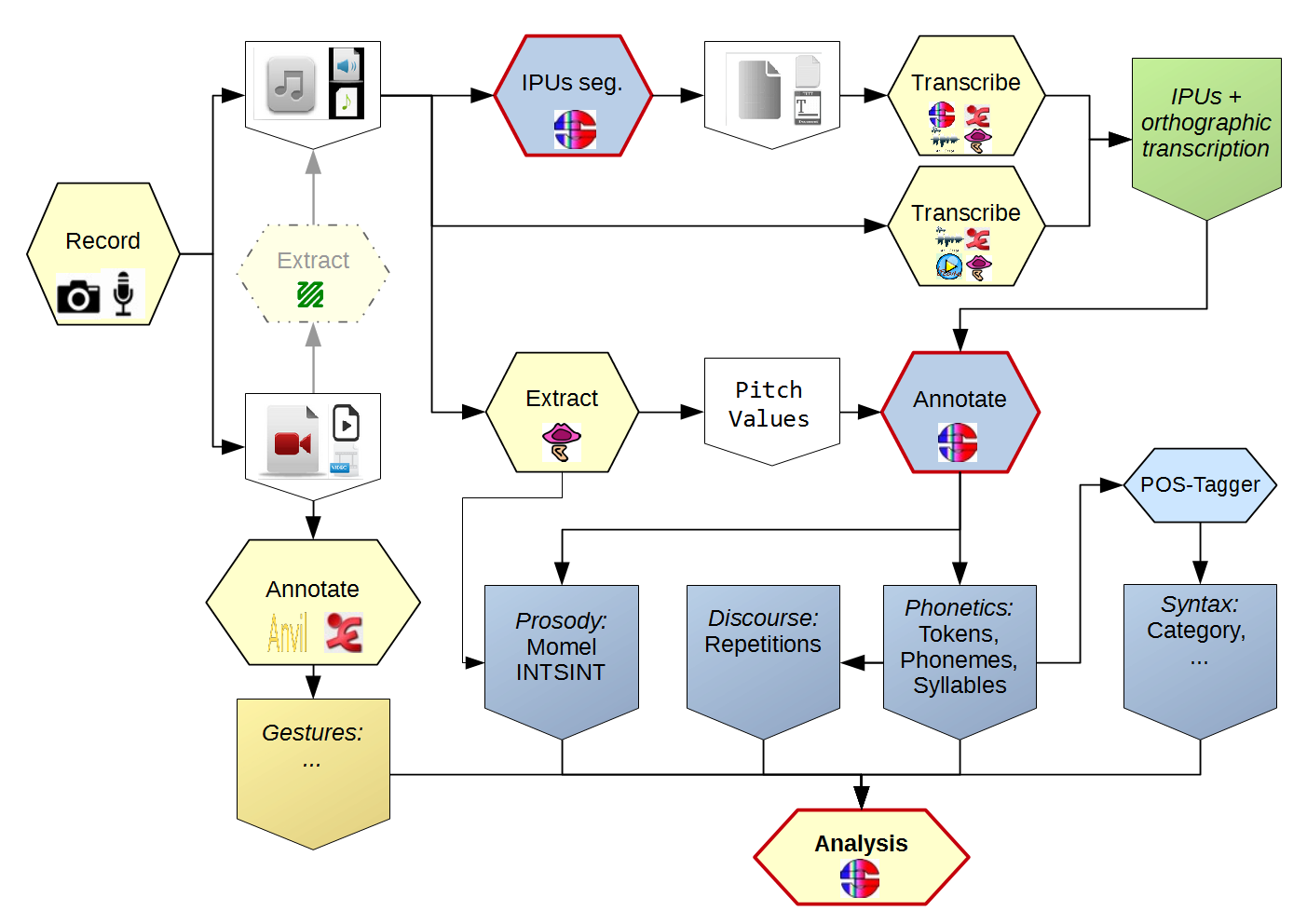
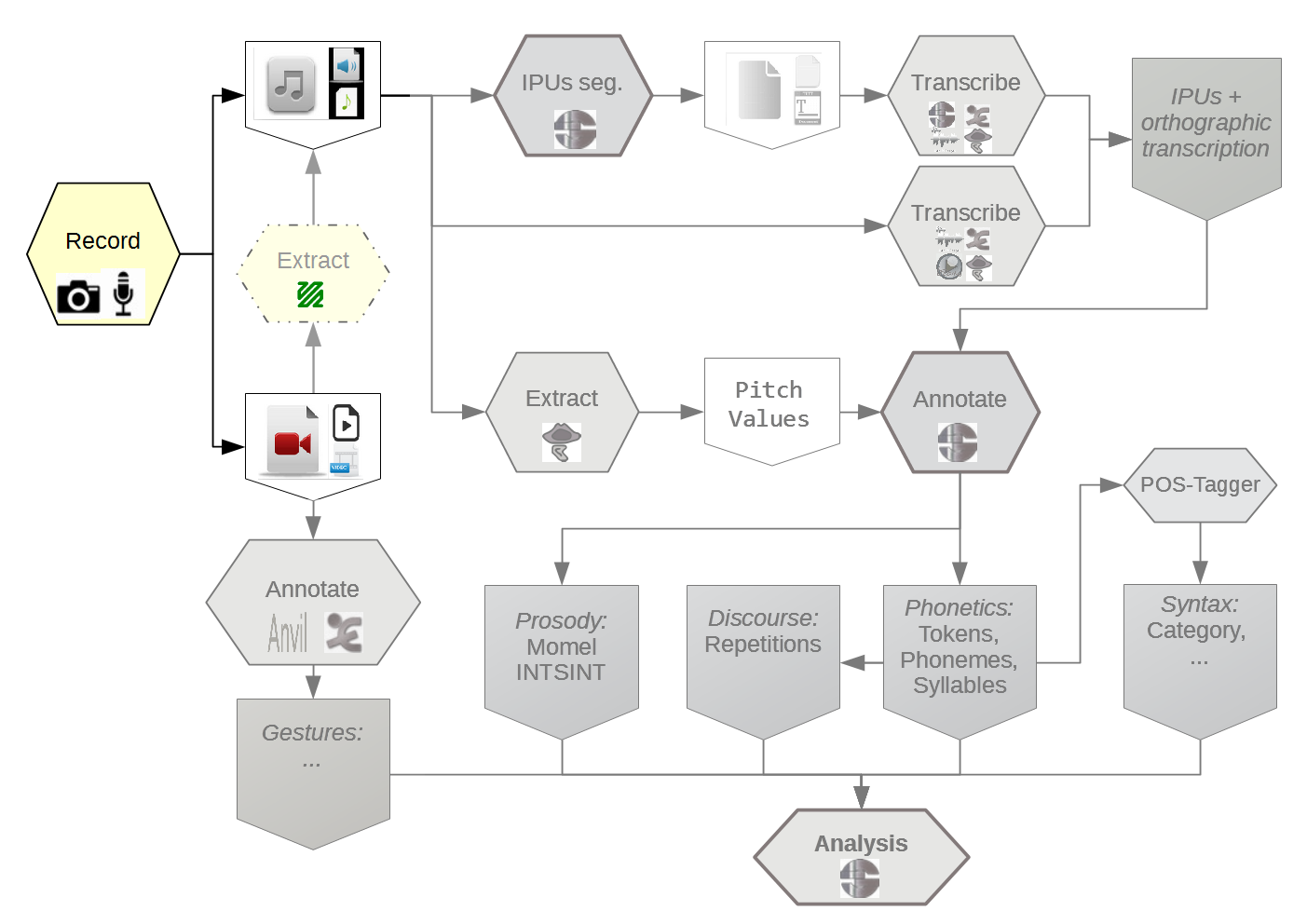



The number of devices is also important.
Lack of standardization means that fewer researchers will be able to work with those signals.

A short list of software we already tested and checked:
![]()
![]()
![]()
![]()
![]()

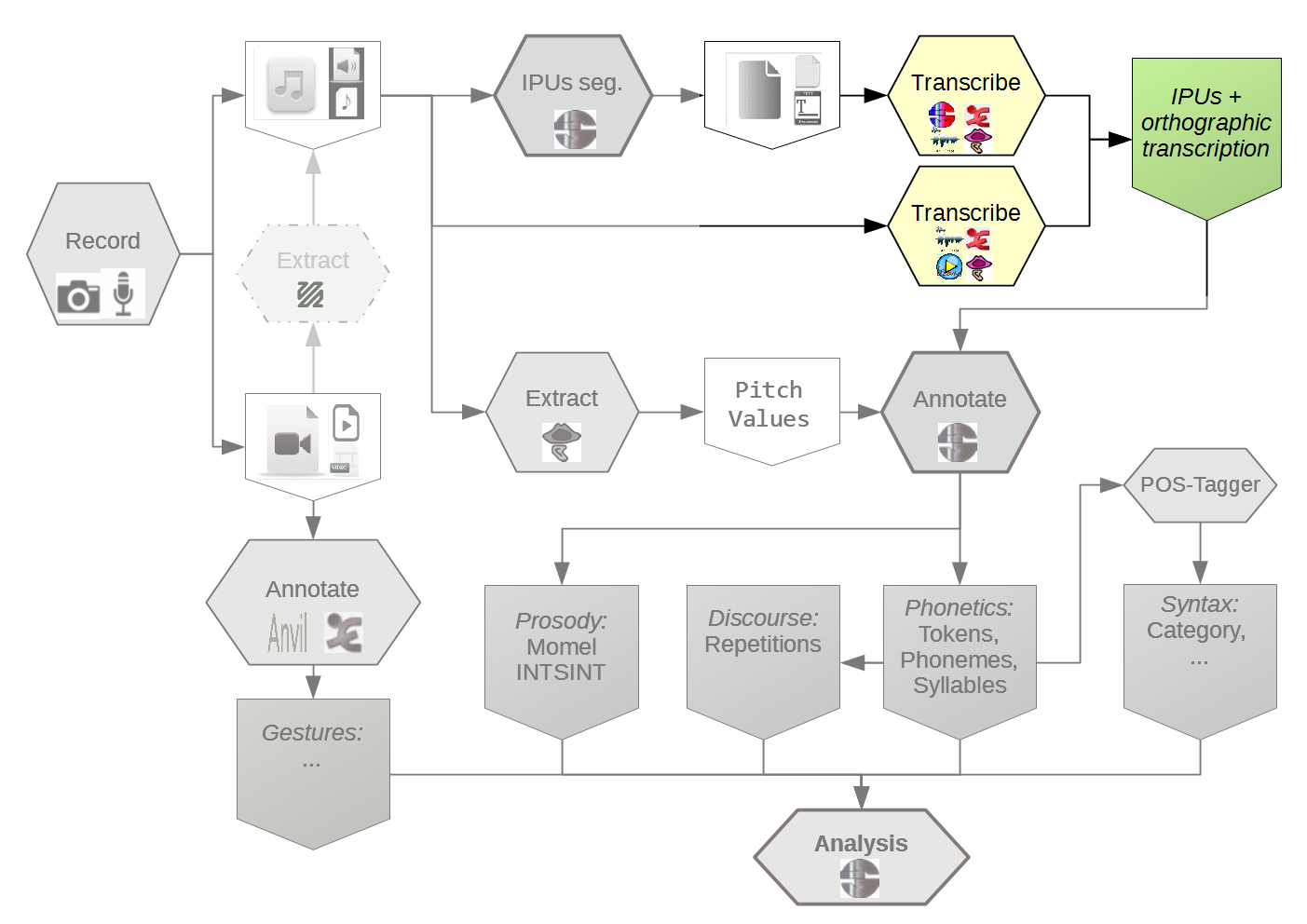

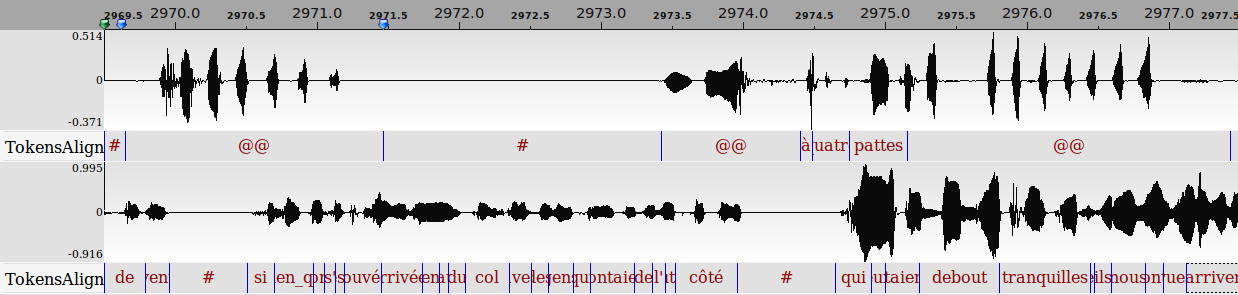

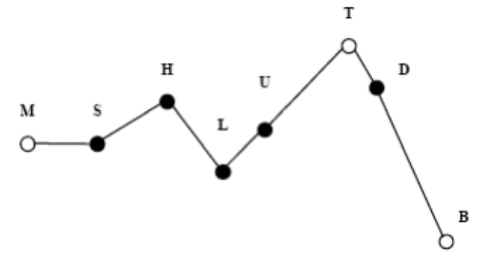
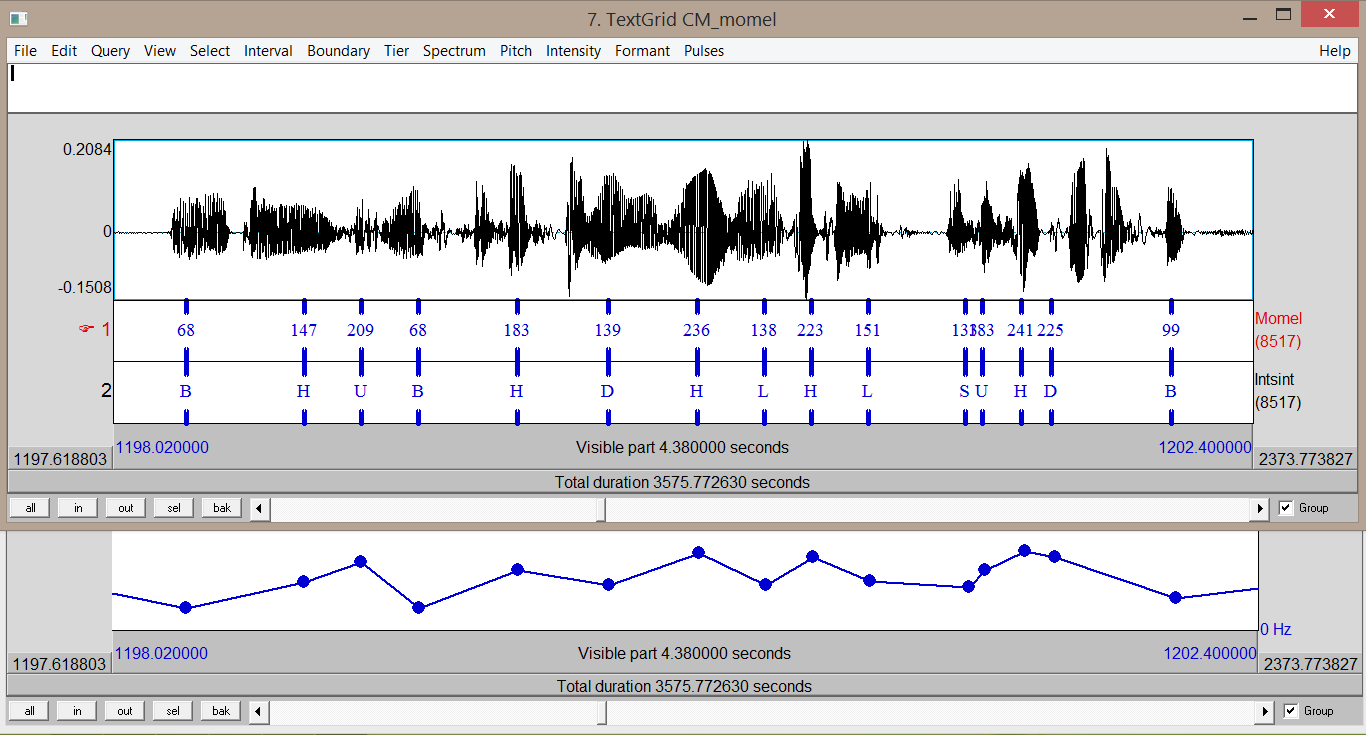
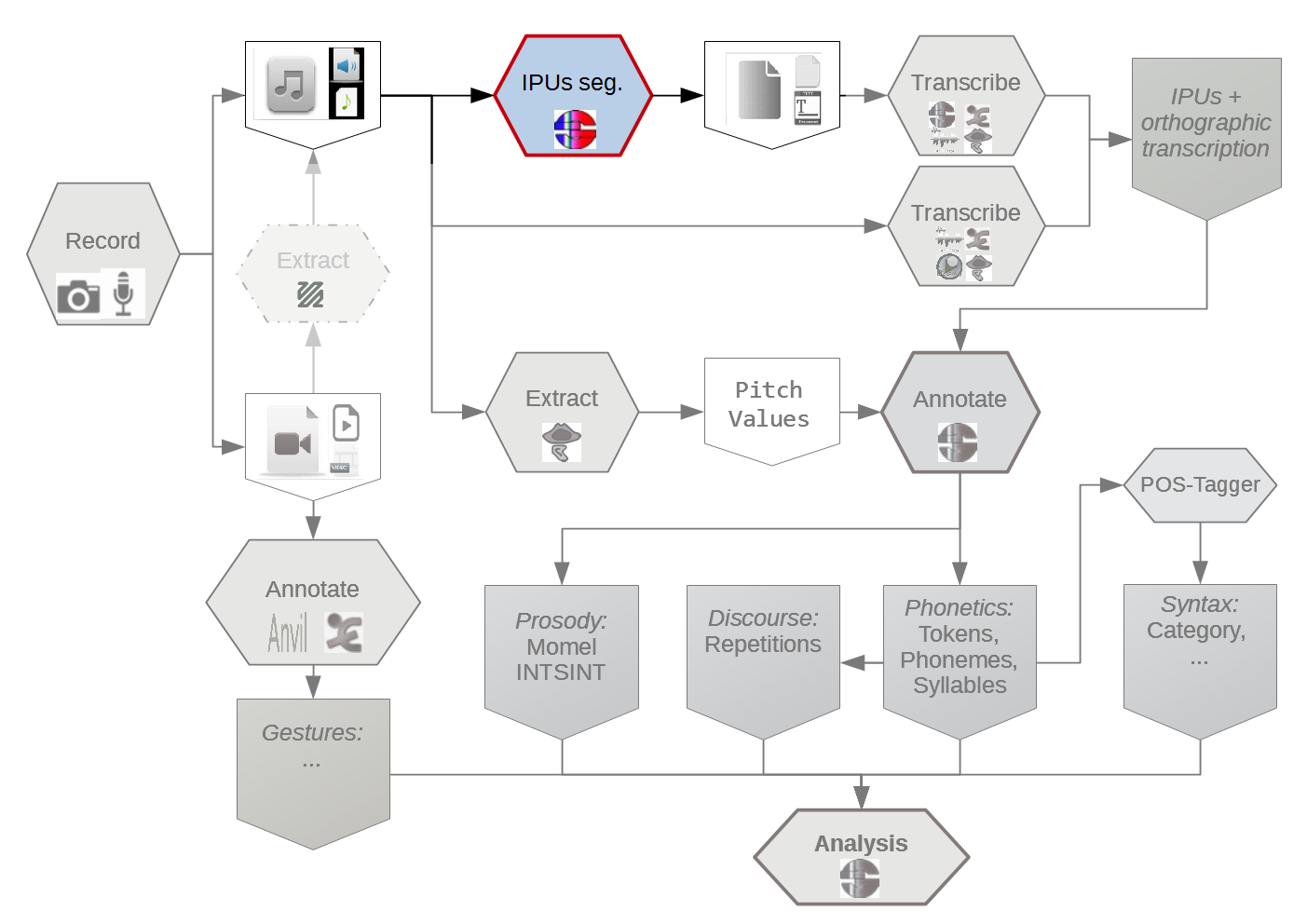
By convention, spaces separate words, dots separate phones and pipes separate phonetic variants of a word. For example, the transcription utterance:


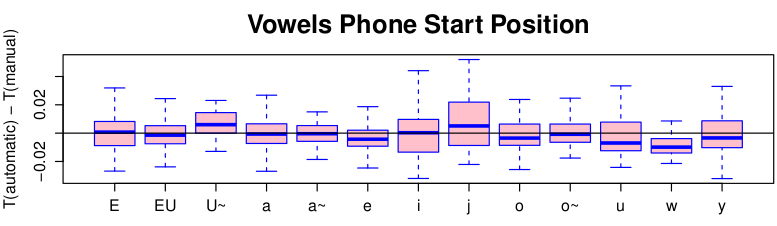
Manual alignment has been reported to take between 11 and 30 seconds per phoneme.
(Leung and Zue, 1984)



SPPAS (python+Julius), available for English, French, Italian, Spanish, Catalan, Polish, Japanese, Mandarin Chinese, Taiwanese, Cantonese