To sum-up
- Methodology and software for the semi-automatic annotation and analysis of speech: Human Language Technology meets Linguists
- Brigitte Bigi, Daniel Hirst and Dafydd Gibbon
- SPPAS: automatic speech segmentation
- Momel and INTSINT: modelling of pitch contours and microprosody
- TGA: analysis of interpausal time groups
Corpora
- CID - Corpus of Interactional Data
- GrenelleII corpus:
- Aix MapTask:
- DVD corpus:
 Screenshots of 4 corpora (left to right): CID, GrenelleII, Aix MapTask, DVD
Screenshots of 4 corpora (left to right): CID, GrenelleII, Aix MapTask, DVD
CID - Corpus of Conversational Data
- Face-to-face conversations in French
- Created by R. Bertrand and B. Priego-Valverde
- 8 semi-guided dialogs (110,000 words)
- Recorded in 2003 and 2005
- Available at:
- Corpus description:
(Bertrand et al. 2008)
- Multimodal annotations:
(Blache et al. 2010)
CID - Current annotations (1)
- Enriched orthographic transcription (manual)
- time-aligned at the utterance level (automatic)
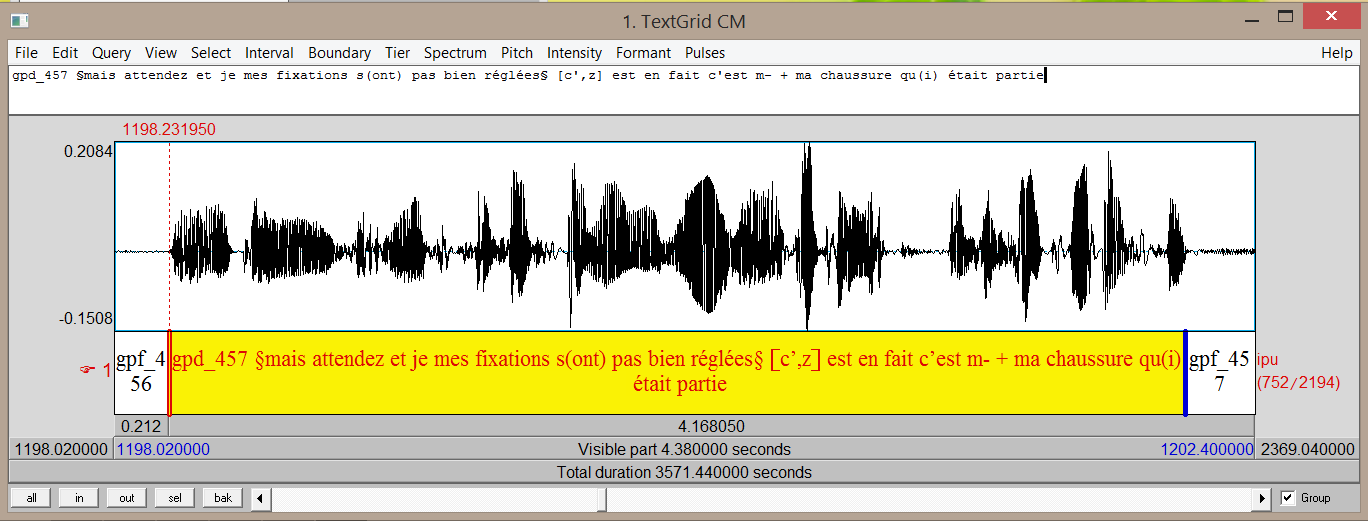
CID - Current annotations (2)
- Time-aligned phonemes and tokens and events like noises, laughter (automatic)
- Time-aligned syllables (automatic)
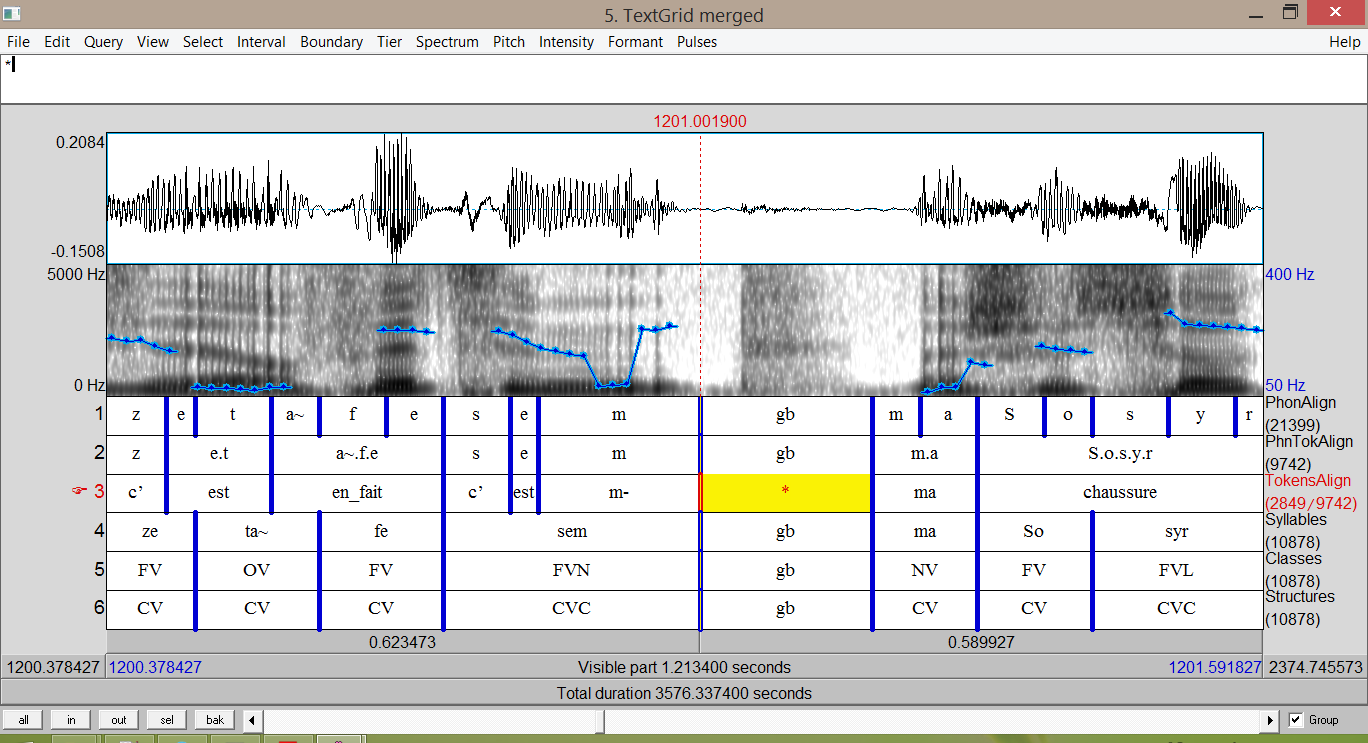
CID - Current annotations (3)
- Prosodic contours (manual)
- Momel - Modelization of melody (automatic)
-
INternational Transcription System for INTonation (automatic)
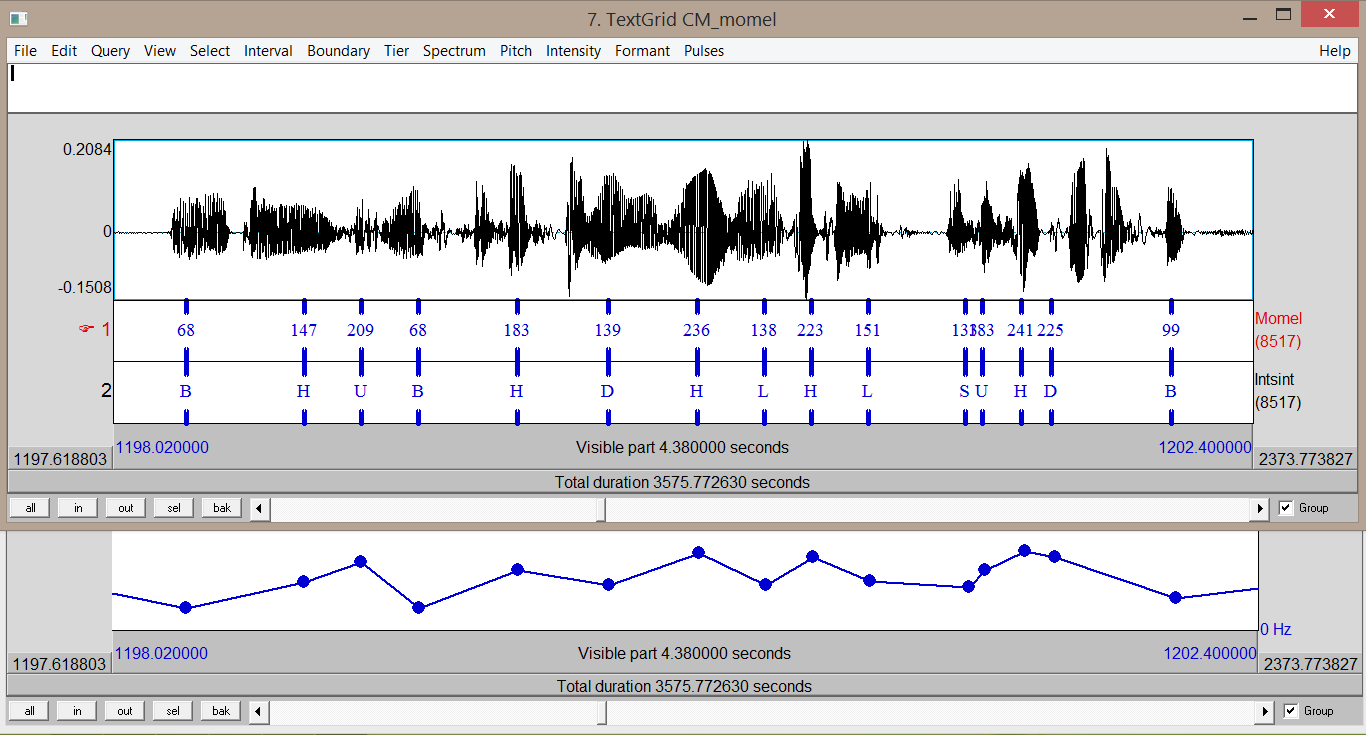
CID - Current annotations (4)
- Morpho-syntax and syntax time-aligned at the token level (automatic);
- Time-aligned lemmas (automatic);
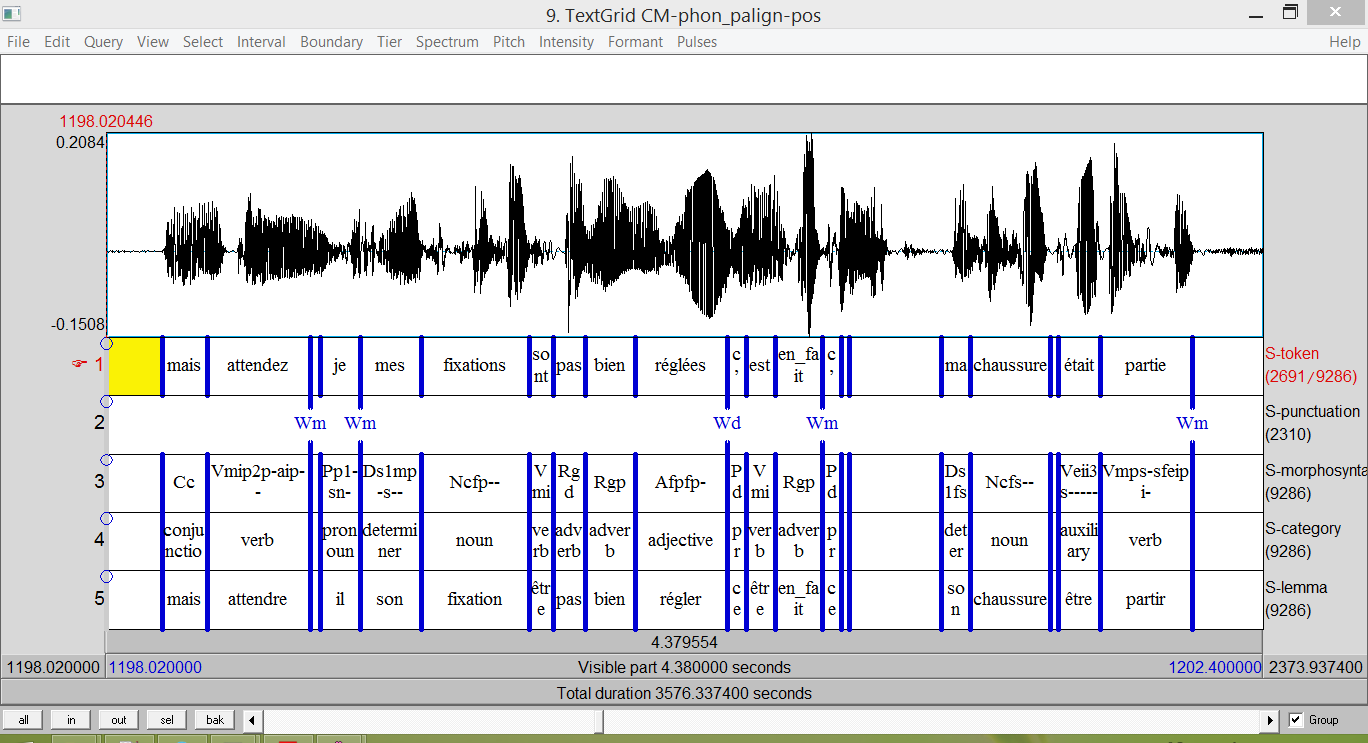
CID - Current annotations (5)
- Dysfluencies (manual)
- Discourse and interaction (manual)
- Other- and Self- Repetitions (semi-automatic)

CID - Current annotations (6)
- Gestures: postural, face, hands (manual)
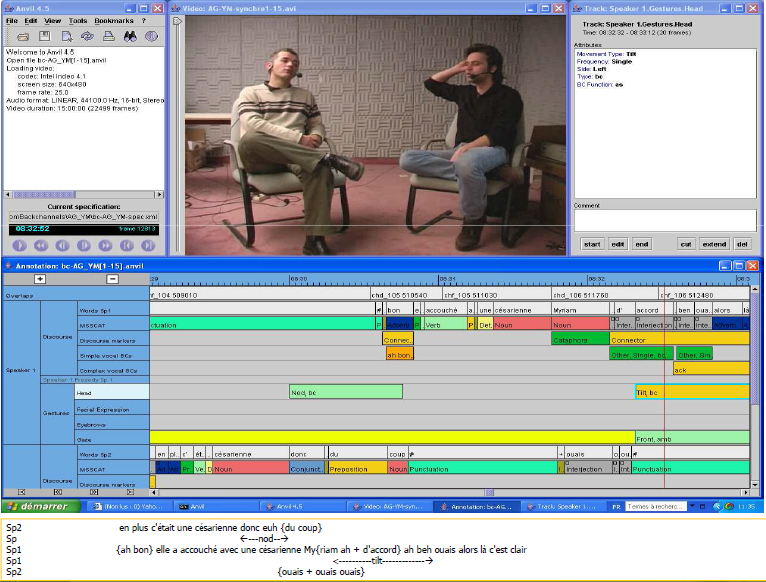
GrenelleII
- Video downloaded from a FTP server (after authorization), a flv file with poor quality
- Audio extracted from the video
GrenelleII: annotations
- Enriched orthographic transcription (manual)
- time-aligned at the utterance level (automatic)
- Time-aligned phonemes, tokens and events (automatic)
- Time-aligned syllables (automatic)
- Prosodic contours and intonation (manual)
- Morpho-syntax time-aligned at the token level (automatic)
- Self-repetitions (semi-automatic)
- Interruptions (manual)
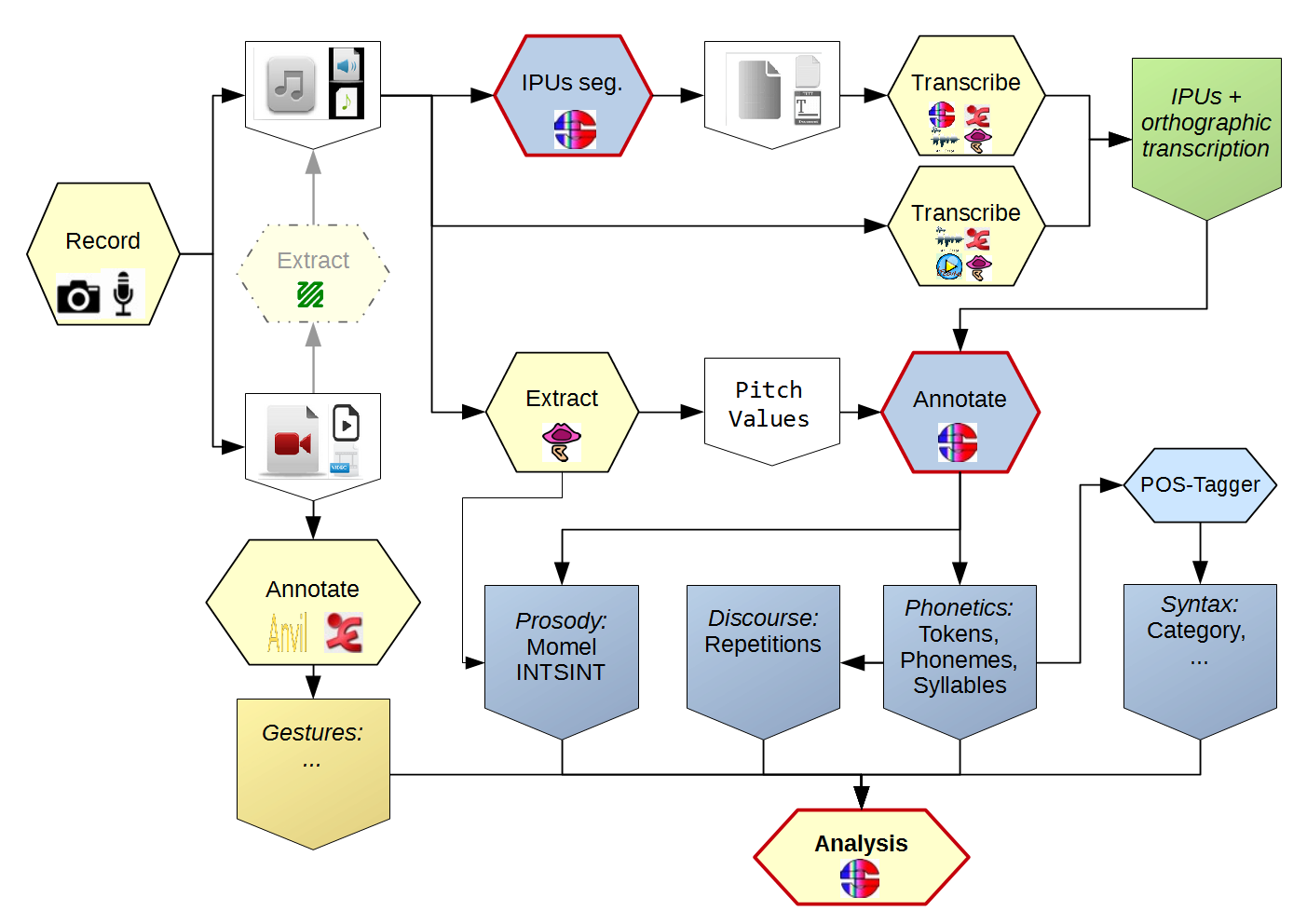
Corpus creation workflow