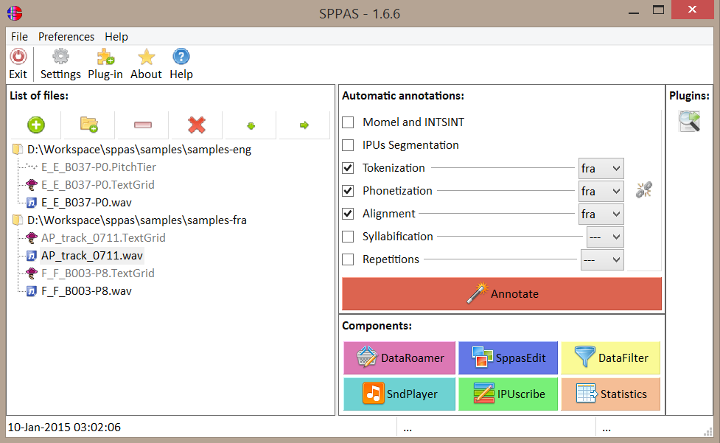
About annotation
- Tasks:
- Segmenting
- Labelling
It is a common practice in Corpus Linguistics to admit that annotating is an inherently ongoing process.
Manual vs Automatic

It is a common practice in Corpus Linguistics to admit that annotating is an inherently ongoing process.
Manual vs Automatic
Linguistics data are annotated several times by one or several annotators, each one annotates according to his/her knowledge, beliefs and uncertainty.

In metrology, physics, and engineering, the uncertainty or margin of error of a measurement is stated by giving a range of values likely to enclose the true value. This may be denoted by error bars on a graph, or by the following notations:






 vs
vs 
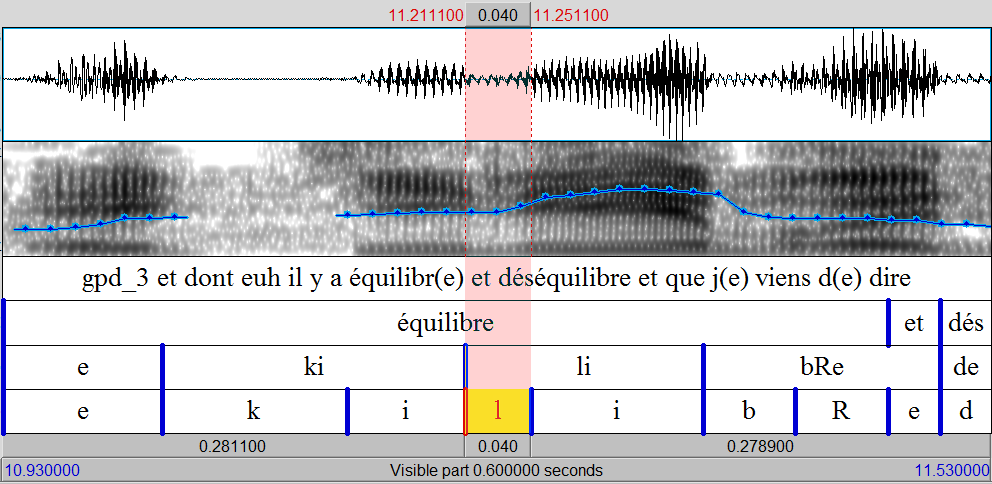



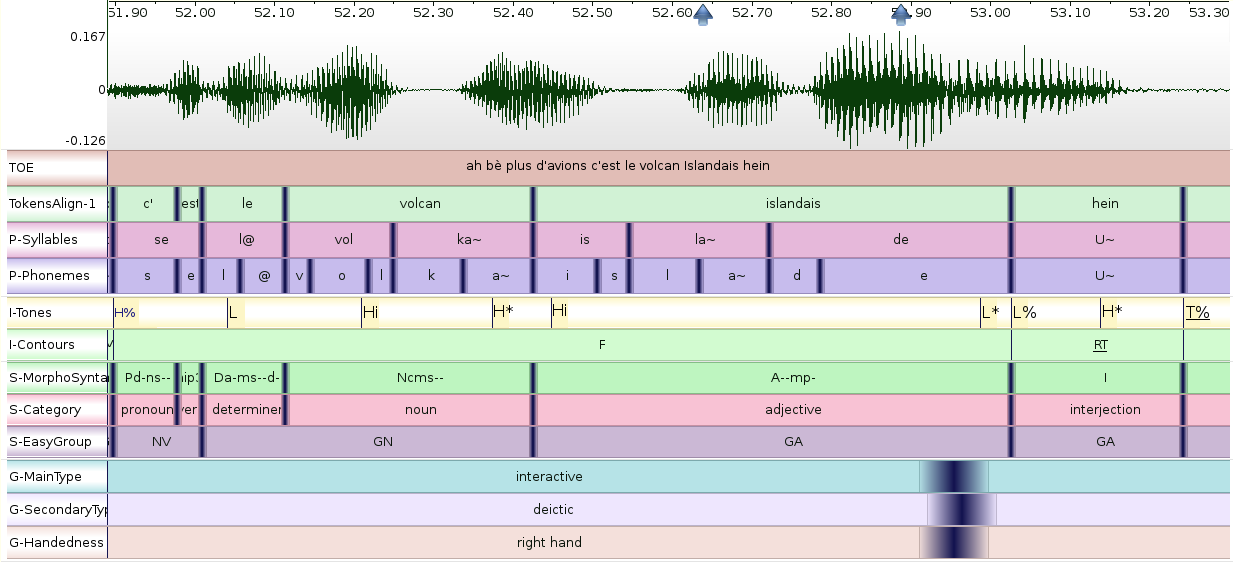
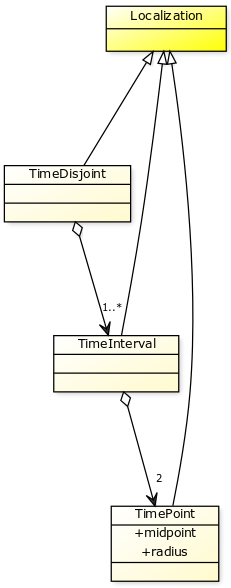
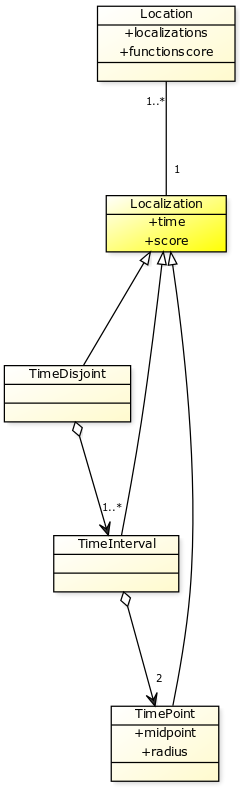
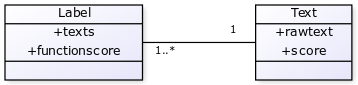
Allow a multiple label selection and assign a score to each possible label.
Notice that the label is then a list of pairs text/score but not a 2-tuples: two labels are equals if their texts are equals regardless of their scores.
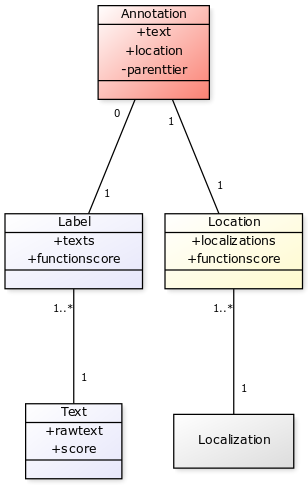
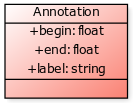
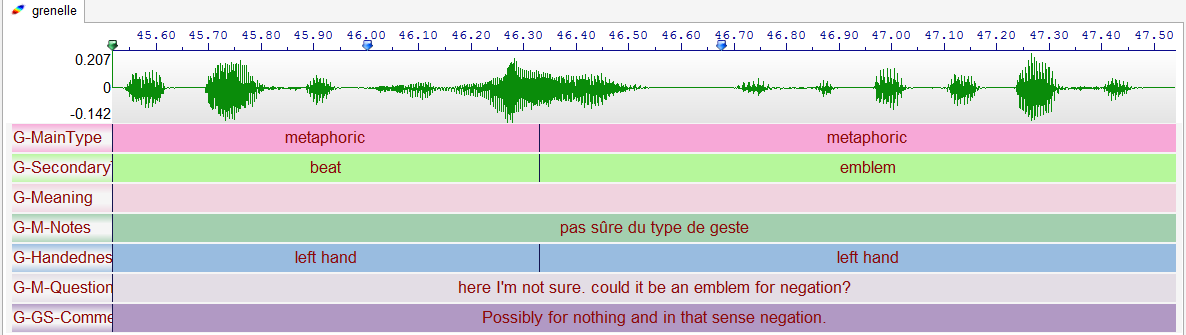
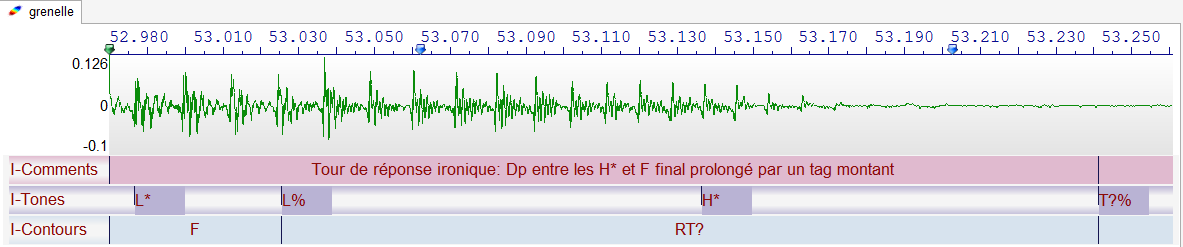
An ambiguous label, at an ambiguous location with imprecise time localizations: