Alignement temporel : de l'orthographique à la phonétique
Brigitte Bigi
Atelier OACQUIL
13 janvier 2026
Transcrire et aligner de la parole
Hésitation:
Rires:
Mots inventés ou régionaux :
Hypo-articulation:
Réparations, répétitions, mots tronqués :
Autres : élisions, bruits, etc.
non mais @ je sais pas tu ne tu te vois nous parler + on- moi je nous par- je n- @ je nous parlais
Pour aligner, tout ce qui est dans le signal audio doit être transcrit.
Ce que je vais vous faire entendre correspond à de la parole spontanée ordinaire.
On y trouve des hésitations, des amorces, des répétitions, parfois des mots tronqués ou des rires.
Ces phénomènes ne sont pas des “bruits” à éliminer : ils font partie du signal.
Dès lors, transcrire ne consiste pas à produire une version standardisée du discours,
mais à représenter ce qui est effectivement audible.
Pour l’alignement, ce point est central :
la synchronisation temporelle repose sur une correspondance stricte entre le signal et la transcription.
Toute omission ou réécriture introduit un décalage.
Cadre théorique
À partir de ce constat, deux principes structurent le cadre.
Les deux idées clés
(1) La synchronisation temporelle de toutes les annotations est
le point d'entrée de la multimodalité.
Corpus Grenelle II (2010)
Cette première idée est centrale.
Toutes les annotations sont synchronisées sur le même axe temporel, celui du signal.
Concrètement, cela veut dire que chaque annotation est définie par un intervalle de temps : un début et une fin.
Cet intervalle sert de repère commun, quel que soit le niveau descriptif.
Cela signifie que les niveaux descriptifs ne sont pas indépendants :
ils sont tous ancrés dans le temps, et donc comparables entre eux.
On peut, par exemple, relier un événement au niveau du mot à ce qui se passe au niveau des sons, ou inversement, uniquement parce qu’ils partagent la même référence temporelle.
C’est cette synchronisation qui rend possible la multimodalité :
si l’on annote aussi des événements non verbaux — gestes, regards, mouvements — eux aussi sous forme d’intervalles temporels, alors la mise en relation devient immédiate.
On ne rapproche pas des objets “par interprétation” : on les met en relation parce qu’ils sont situés sur la même ligne temporelle.
Les deux idées clés
(2) Tout ce qui est automatisable... doit être automatisé.
Machine
Humain
rapide, répétable, taux d'erreur
lent, coûteux, peu d'erreurs
quantité
qualité
🧩 L'automatisation, oui — mais dans un cadre linguistique maîtrisé...
L'humain est requis durant le processus et/ou après !
Dès lors que les annotations sont formalisées et synchronisées temporellement,
certaines tâches deviennent automatisables.
Il s’agit en priorité des tâches répétitives, systématiques, et bien définies :
segmenter, convertir, aligner, appliquer des règles de façon homogène sur de grands volumes de données.
L’automatisation n’a pas pour objectif de remplacer l’analyse linguistique,
mais de la rendre possible à l’échelle des corpus actuels.
Elle permet de traiter rapidement, de manière cohérente, et reproductible.
Malgré tout, l’intervention humaine reste indispensable :
en amont, pour définir les conventions et les catégories ;
en aval, pour contrôler, corriger et interpréter les résultats.
La difficulté
When annotating corpora at multiple linguistic levels, annotators
may use different expert tools for different phenomena or types of
annotation. These tools employ different data models and accompanying
approaches to visualization, and they produce different output formats.
(Chiarcos et al. 2008)
⏰ Le choix des outils logiciels... se fait en amont de la captation.
Il conditionne la qualité, la pérennité et la réutilisation du corpus.
Quand on multiplie les niveaux d’annotation, on multiplie aussi les outils.
Chaque outil a son propre modèle de données, sa propre visualisation, ses propres formats de sortie.
Cela complique fortement l’articulation entre annotations.
Le point important ici est temporel et méthodologique :
le choix des outils ne se fait pas après coup.
Il se fait avant la captation, parce qu’il conditionne tout le reste.
Le choix des outils logiciels 🤯 …
Science ouverte et principes FAIR
Licence libre / open source
Utilisable avant, pendant et après la constitution du corpus
Multiplateforme, accessible aux linguistes
Adapté aux tâches visées (annotation, alignement)
Interopérable : formats standards, import/export
SPPAS remplit ces critères : libre, multiplateforme, formats multiples,
automatisation et reproductibilité.
Ici, je rappelle un principe général : science ouverte et principes FAIR.
Un outil doit être libre, interopérable, et utilisable tout au long de la vie du corpus.
Ce sont des contraintes méthodologiques, pas idéologiques.
Elles conditionnent la pérennité des données, leur partage, et leur réutilisation.
SPPAS répond à ces critères.
SPPAS : segmentation automatique de la parole
Prix Science Ouverte du logiciel libre de la recherche
version 1version 2version 3 & 4version 5 (à venir)
SPPAS est un logiciel libre dédié à l'annotation automatique de la parole.
Il est utilisé ici principalement pour la segmentation et l'alignement.
Je montre rapidement son évolution et sa reconnaissance institutionnelle,
non pas pour faire un bilan, mais pour situer l’outil :
outil mature, utilisé, éprouvé, et reconnu institutionnellement.
SPPAS version 4.30 (Décembre 2025)
24 annotations
15 langues
analyses des annotations
conversion de fichiers
+30 : publications
>580 : citations
>1650 : téléchargements en 2025
110k lignes de Python
90k lignes de commentaires et docstrings Python
170 : pages de documentation
1 : prix du ministère
Cette slide donne un ordre de grandeur.
Nombre d’annotations, de langues, de publications, de téléchargements.
L’objectif n’est pas le détail,
l'objectif est de montrer que l’outil couvre un large spectre de besoins
et qu’il est utilisé sur des volumes importants.
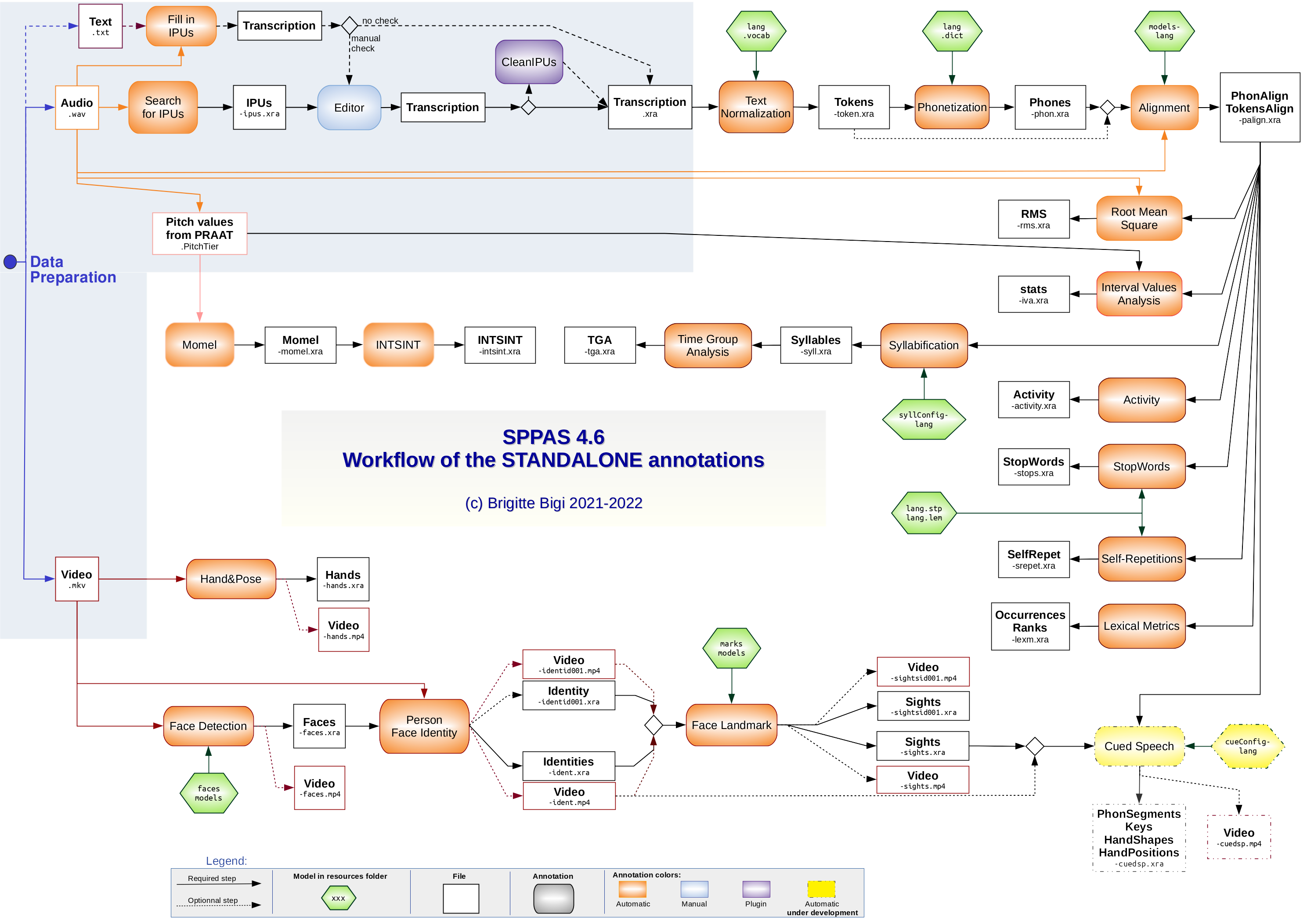
Pipeline outil/tâche 🧱
On arrive maintenant au cœur du processus.
L’annotation est organisée comme un pipeline, avec des étapes clairement identifiées.
La transcription est le point d’entrée.
Tout ce qui suit dépend directement de sa qualité.
Transcription alignée sur le signal ⚙️
SPPAS - Segmentation en IPUs - Inter-Pausal Units
Praat - Transcription orthographique enrichie (TOE), au sein des IPUs
corriger les frontières des IPUs (erreurs de SPPAS),
transcrire.
SPPAS - Normalisation et conversion graphèmes-phonèmes
SPPAS - Alignement en phonèmes et mots
Flux des tâches : de l'audio aux phonèmes et mots alignés
Sur le plan opérationnel, le traitement commence par une segmentation automatique en unités inter-pausales.
Ces unités définissent le cadre temporel dans lequel la transcription est réalisée.
La transcription est donc le point d’entrée linguistique,
la segmentation le point de départ technique.
La transcription orthographique enrichie est ensuite réalisée dans ces unités,
avec un contrôle humain ciblé.
Les étapes suivantes — normalisation, phonétisation, alignement —
sont entièrement automatisées.
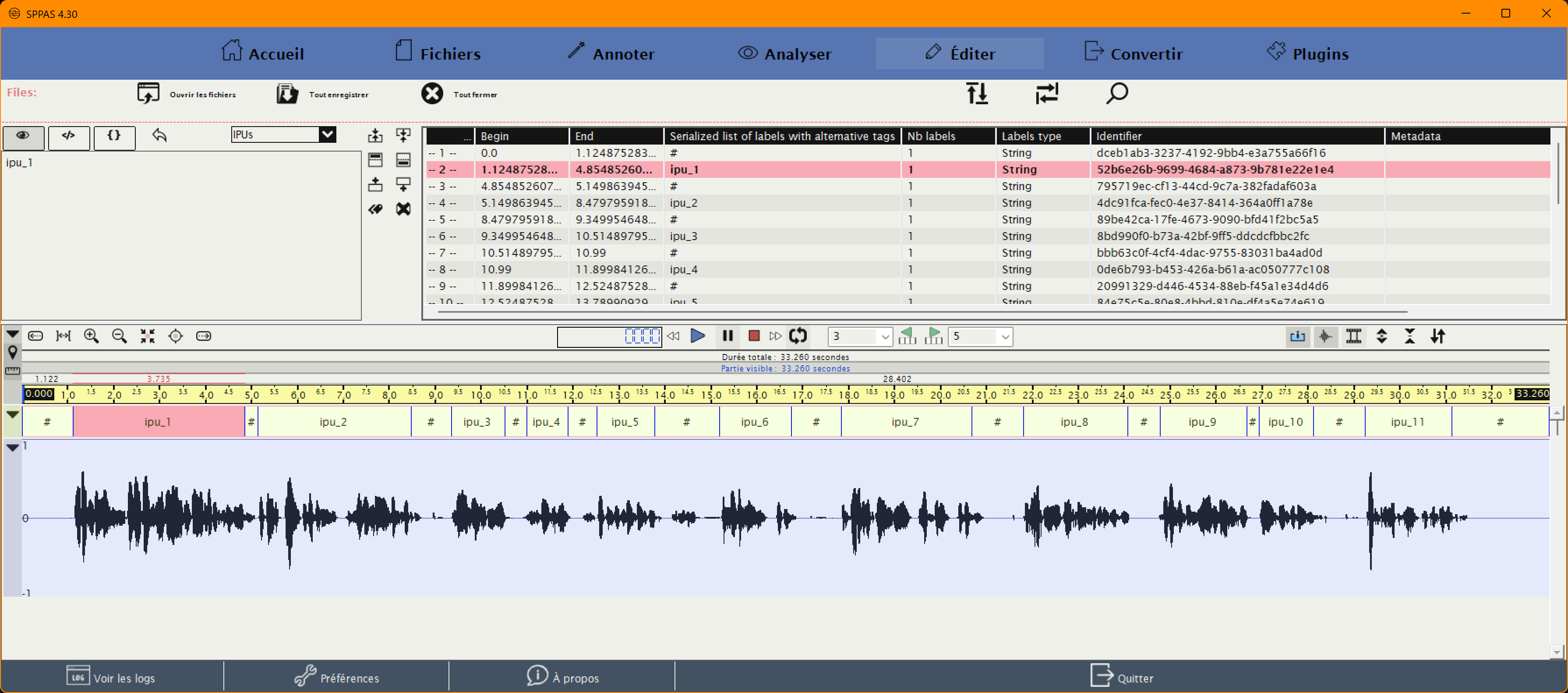
Segmentation en unités inter-pausales
Détermine les segments audibles
Exemple de segmentation en IPUs
La segmentation vise à détecter tous les segments potentiellement audibles.
L’outil privilégie volontairement la sur-détection plutôt que l’omission.
Le risque accepté est celui de segments en trop,
le risque évité est celui de segments manquants.
Le contrôle humain consiste alors à corriger ou supprimer des segments détectés,
sans avoir à parcourir l’intégralité du signal,
ce qui réduit considérablement le temps de vérification.
La Transcription Orthographique Enrichie 🧬
Il faut une convention qui permet d'automatiser à la fois les annotations :
(morpho-)syntaxique, et
phonétique, et
autres !
La TOE encode les décisions linguistiques humaines pour permettre l’automatisation.
Je montre ici deux exemples concrets.
On y voit une élision, et une prononciation inattendue.
La transcription repose sur une convention explicite.
Cette convention doit permettre à la fois des traitements syntaxiques
et des traitements phonétiques.
La transcription n’est donc pas seulement un texte :
elle encode des décisions linguistiques.
Exemples de Transcription Orthographique Enrichie
Exemples d'extraits audio des corpus CID et Cheese!
ah mais justement c'était pour vous vendre bla bla bla bl-
le mec il te l'a emboucané en plus il lui a acheté le truc
et le mec il est parti je dis putain le mec il voulait
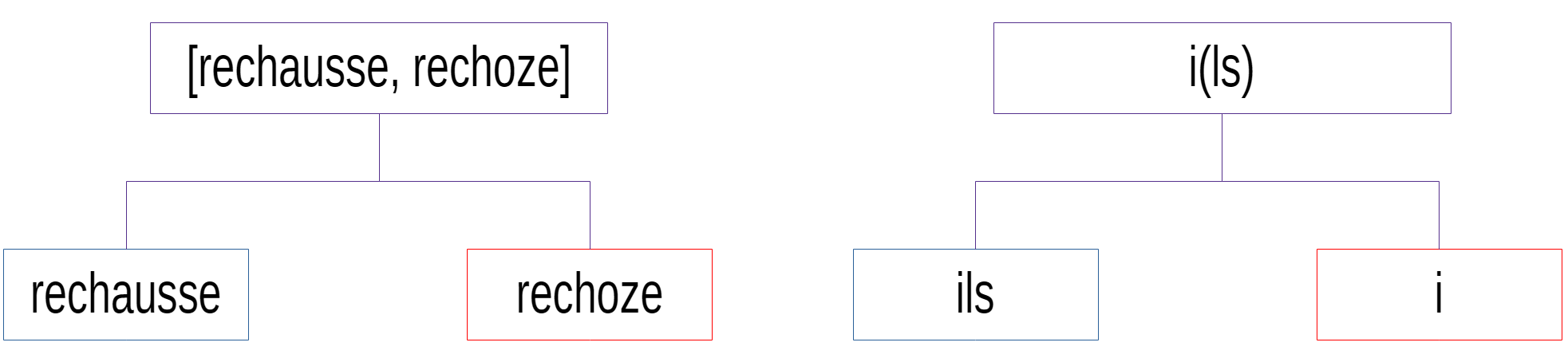
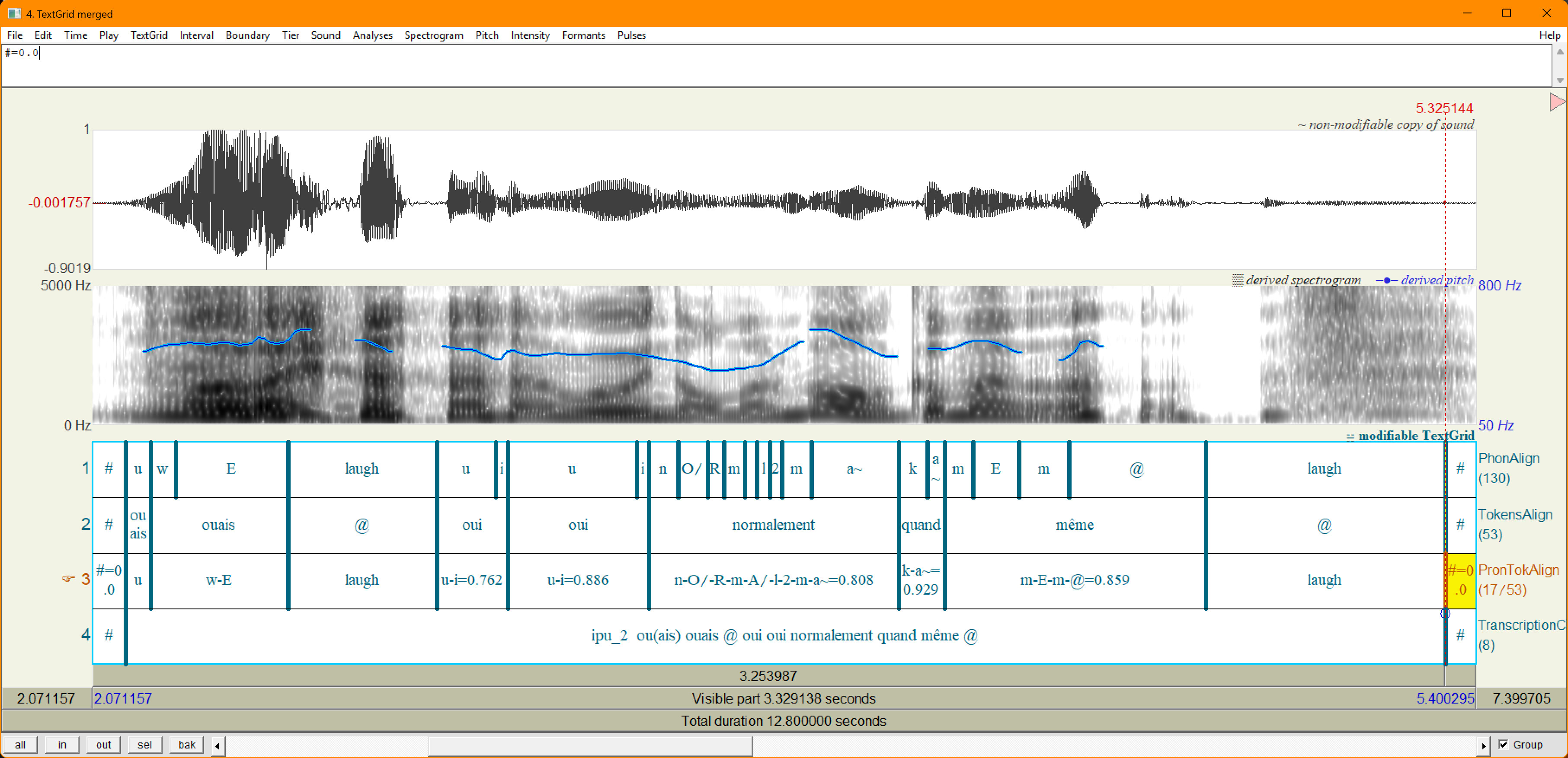
et puis euh bon je [rechausse, rechose] ou(ais) ouais @ oui oui normalement quand même @
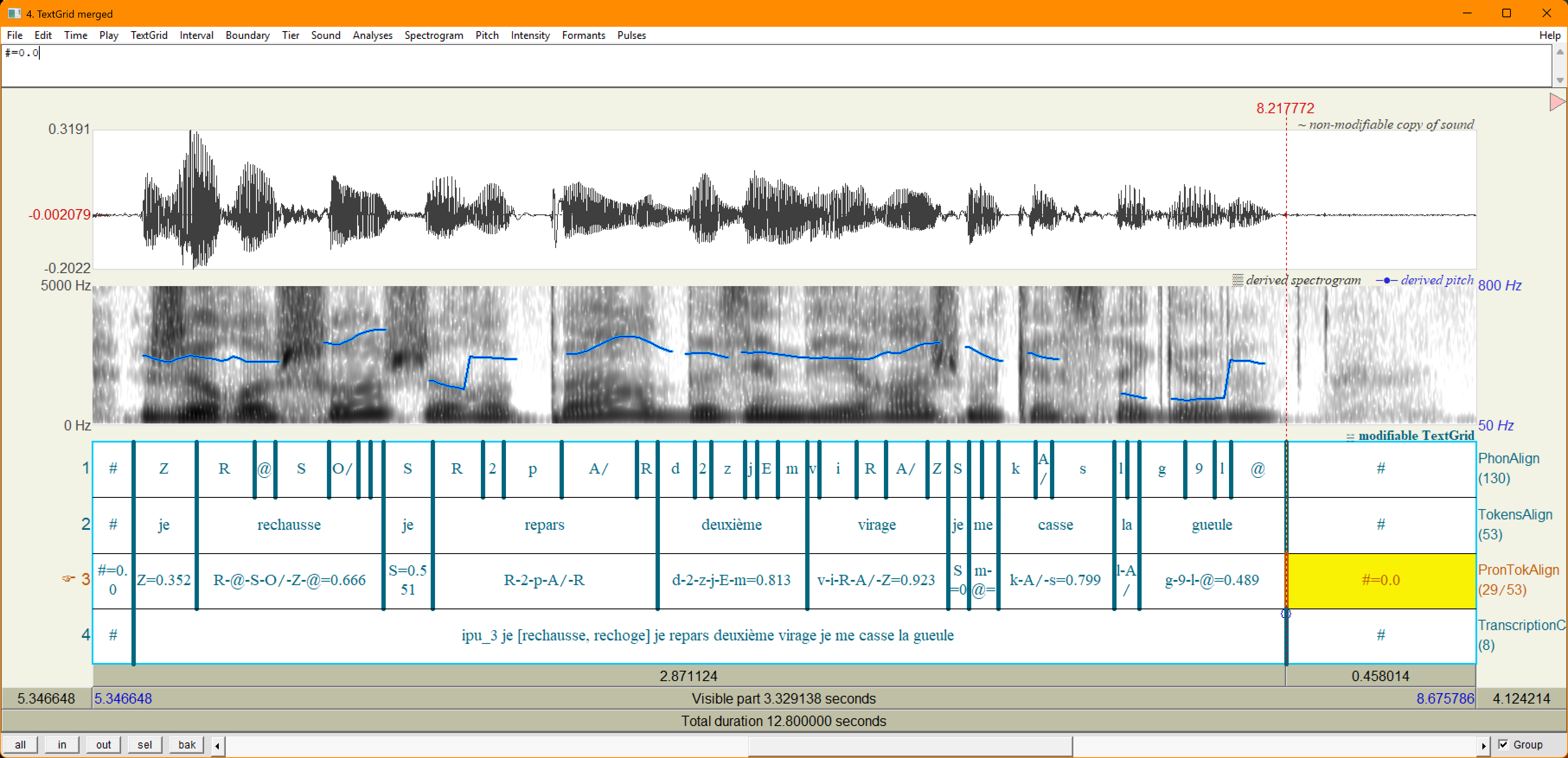
je [rechausse, rechoge] je repars deuxième virage je me casse la gueule m(ais) attends et je mes fixations s(ont) pas bien réglées [c',z] est
en fait c'est m- + ma chaussure qu(i) était partie
Les élisions sont entre parenthèses et les prononciations inattendues avec une double
mention (ortho truquée, ortho standard), les rires avec une arobase, les mots tronqués
avec un 'moins' final, etcétéra.
car ... la convention de transcription ne doit pas faire perdre d'information.
Normalisation et conversion graphèmes-phonèmes
Normalisation : transformation de la transcription enrichie
en formes exploitables automatiquement
Phonétisation : génération de variantes phonétiques
à partir des formes normalisées
À partir de la transcription orthographique enrichie,
la normalisation transforme les formes produites par l’humain
en représentations exploitables automatiquement.
La phonétisation génère ensuite un ensemble de variantes phonétiques possibles.
Ces étapes sont entièrement automatisées.
L’intervention humaine n’est pas requise pour l’exécution,
mais elle reste possible pour adapter les ressources et les paramètres
aux spécificités d’un corpus donné.
Alignement temporel
Mise en correspondance des phonèmes et des mots avec le signal audio
Sélection automatique de la variante phonétique la plus compatible avec le signal
Exemple (variantes) : le mot "petit"
L'alignement choisit automatiquement la variante la plus compatible avec le signal
pti
p@ti
ptit
p@tit
Résultat : toutes les annotations sont synchronisées sur l’axe temporel du signal.
L’alignement met en correspondance les unités linguistiques avec le signal audio.
Lorsqu’il existe plusieurs variantes phonétiques possibles,
l’alignement sélectionne celle qui est la plus compatible avec le signal.
Comme on le voit dans l'exemple avec le mot petit qui peut être prononcé de 4 façons différentes.
Le résultat de l'alignement est un ensemble d’annotations toutes synchronisées temporellement.
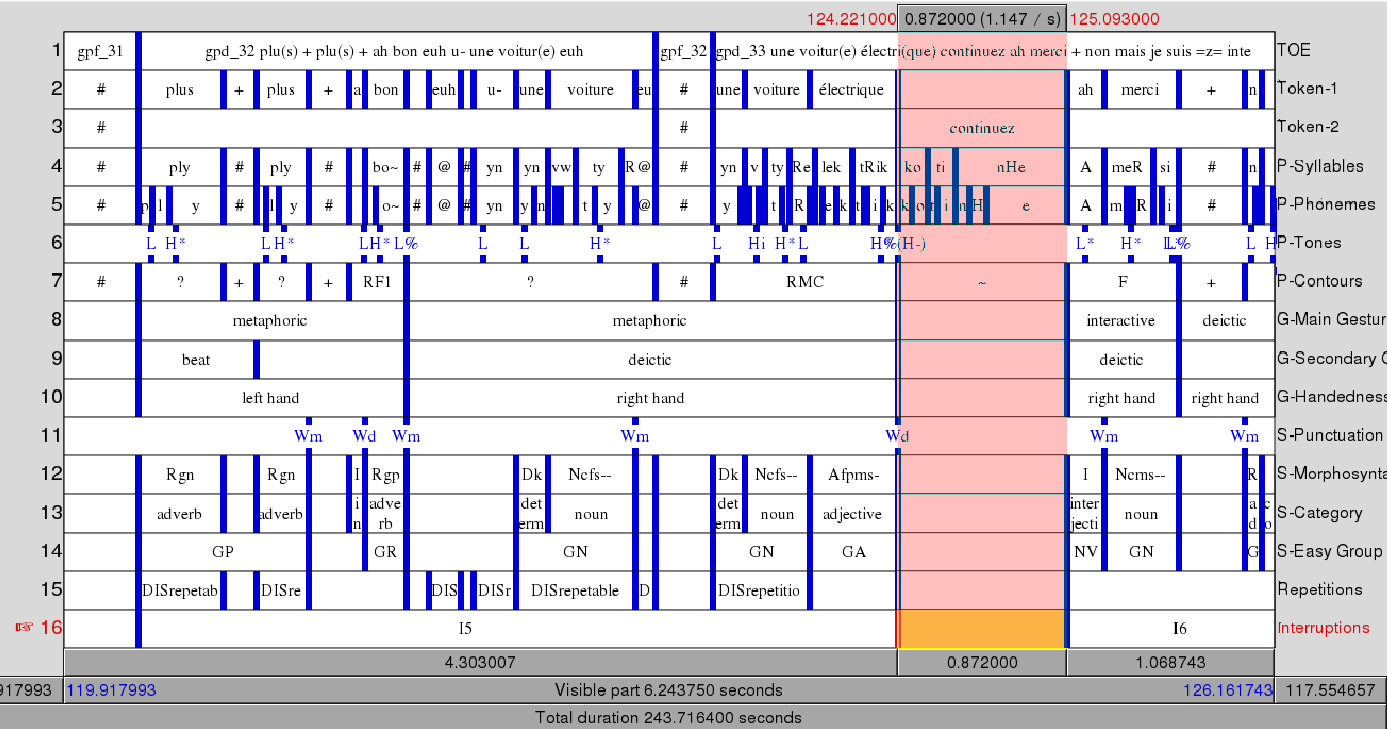
Exemple de résultat, avec rires et élisions
Cet exemple montre le résultat de l’alignement sur une parole conversationnelle.
Exemple de résultat, avec prononciation inattendue
Idem pour ce second exemple.
La suite...
Je termine en ouvrant sur les évolutions récentes.
Un nouveau paradigme avec SPPAS/STT
"Speech-To-Text" (STT) est une annotation proposée dans SPPAS
Utilise Whisper d'OpenAI pour transcrire orthographiquement les IPUs
Édition manuelle pour :
corriger les frontières des IPUs (erreurs de SPPAS)
transcrire, ou corriger / enrichir la transcription (erreurs et manques de Whisper)
Whisper lisse, nettoie, et efface tout ce qui fait la richesse ou
la complexité du langage parlé.
L’intégration d’un module Speech-to-Text modifie une étape du pipeline :
la transcription, auparavant entièrement manuelle, devient partiellement automatisable.
Cette automatisation pose des contraintes nouvelles.
En particulier, l’usage d’outils d’IA impose que le cadre juridique soit explicitement défini.
La conformité au RGPD, ainsi que les politiques institutionnelles en vigueur,
doivent être vérifiées avant toute utilisation sur des données de parole.
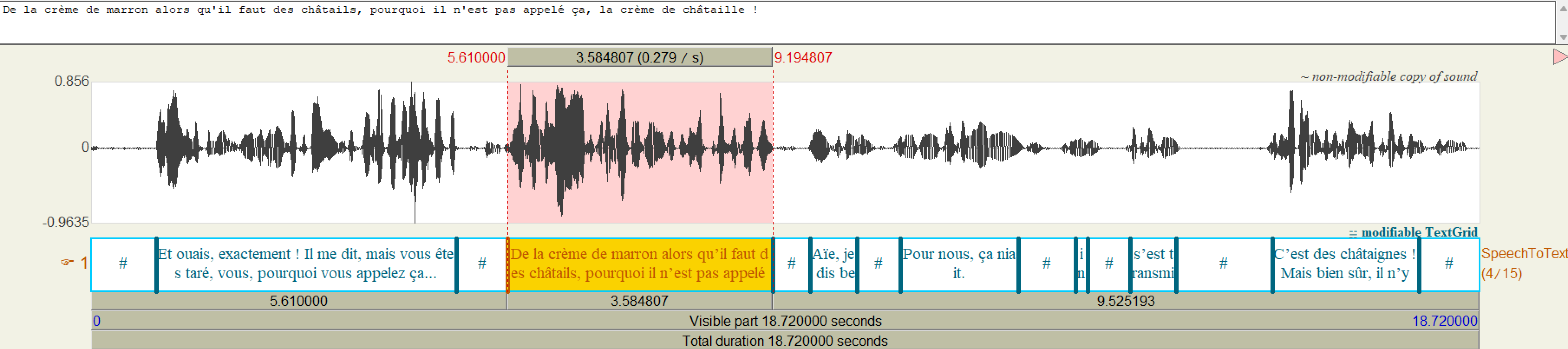
Whisper + SPPAS : exemple
Et ouais, exactement ! Il me dit, mais vous êtes taré, vous, pourquoi vous appelez ça...
De la crème de marron alors qu'il faut des châtails, pourquoi il n'est pas appelé ça, la crème de châtaille !
Aïe, je dis ben...
Pour nous, ça niait.
in the
s'est transmise
C'est des châtaignes ! Mais bien sûr, il n'y a que ça qui est comme...
Cet exemple illustre les limites actuelles. Whisper produit une transcription fluide,
mais il lisse et efface une partie de la complexité du langage parlé.
Cela pose directement la question du compromis
entre automatisation et fidélité au signal,
question que nous discuterons ensuite.
This document is a creative work, the exclusive property of "Laboratoire
Parole et Langage (UMR7309)",
protected by French and international intellectual property law, and licensed under
CC BY-NC-ND (Attribution / Non-Commercial / No Derivatives).
This license permits any distribution (sharing, copying, reproducing,
distributing, communicating), except for commercial purposes,
by any means and in any format, provided that the work is distributed
without modification and in its entirety.
You are free to copy, distribute, and transmit this document, provided that
you credit the
LPL.
je vous remercie pour votre attention blabla, vous trouverez tous les
liens .