the process of taking the orthographic transcription text of
an audio speech segment, like IPUs, and determining where
particular phonemes/words occur in this speech segment.
Definition:
IPUs = Inter-Pausal Units
Data preparation
Audio file with the following recommended conditions:
one file = one speaker = one channel
good recording quality (anechoic chamber)
16000Hz, 16bits
Orthographic transcription:
follow the convention of the software
enriched with: filled pauses; short pauses; truncated words; repeats; noises and laugh items.
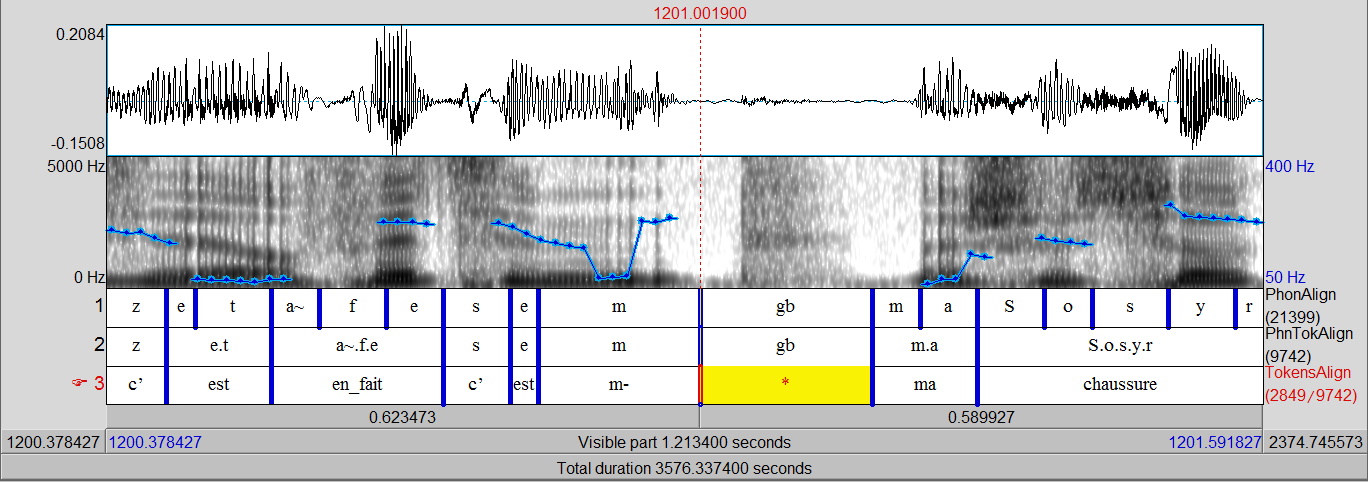
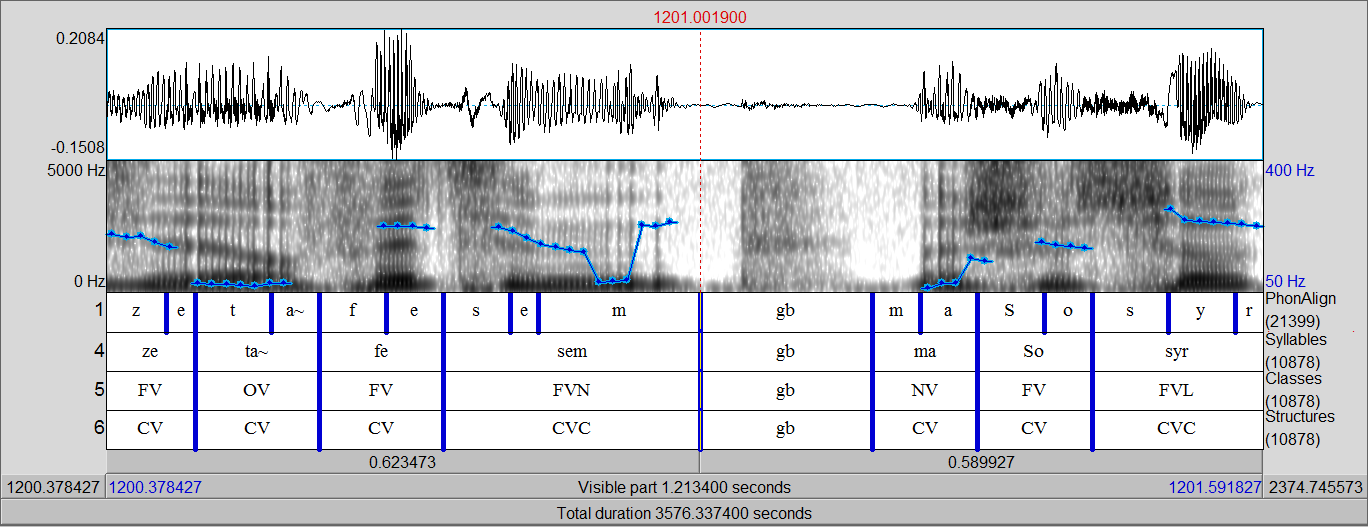
Data preparation: example
An IPU of “Corpus of Interactional Data”
Expected result
Time-aligned phonemes and tokens, including events like noises or laughter
Phonemes and words segmentation: research approach of SPPAS
text normalization
phonetization (grapheme to phoneme conversion)
alignment (speech segmentation)
All three tasks are fully-automatic, but each annotation result can be manually checked.
Text Normalization
Any system that deals with unrestricted text needs the text to be normalized.
It’s the process of segmenting a text into tokens.
Automatic text normalization is mostly dedicated to written texts, in the NLP community
Text normalization development is commonly carried out specifically for each language and/or task
even if this work is laborious and time-consuming. Actually, for many languages there has not been
any concerted effort directed towards text normalization.
Text Normalization: SPPAS approach
A generic approach:
a method as language-and-task independent as possible.
this enables adding new languages quickly when compared to the development of such tools from
scratch.
This method is implemented as a set of modules that are applied sequentially to the text corpora.
The portability to a new language consists of:
inheriting all language independent modules;
(rapid) adaptation of other language dependent modules.
Text Normalization main steps
Split:
use whitespace or characters to split the utterance into separated strings
Replace symbols by their written form:
based on a lexicon
° is replaced by degrees (English), degrés (French), grados (Spanish), gradi (Italian), mức
độ (Vietnamese), 度 (Chinese), du (Chinese pinyin and Taiwanese)
² is replaced by square (English), carré (French), quadrados (Spanish), quadrato (Italian),
bình phương (Vietnamese), 平方 (Chinese), ping fang (Chinese pinyin)
Text Normalization main steps (continued)
Segment into words:
fixes a set of rules to segment strings including punctuation marks
based on a lexicon and rules
aujourd’hui, c’est-à-dire
porte-monnaie, cet homme-là, voulez-vous
poudre d’escampette, trompe-l’oeil, rock’n roll
Text Normalization main steps
Stick, i.e. concatenate strings into words
based on a dictionary with an optimization criteria: the longest matching algorithm
Speech transcription includes speech phenomena like:
specific pronunciations: [example,eczap]
elisions: examp(le)
Then two types of transcriptions can be automatically derived by the automatic tokenizer:
the “standard transcription” (a list of orthographic tokens/words);
the “faked transcription” that is a specific transcription from which the obtained phonetic tokens
are used by the phonetization system.
Text Normalization of speech transcription: example
Transcription:
mais attendez et je mes fixations s(ont) pas bien réglées [c’,z] est en fait c’est m- + ma chaussure
qu(i) était partie
Tokens standards:
mais attendez et je mes fixations sont pas bien réglées c’ est en_fait c’est ma chaussure qui était
partie
Tokens:
mais attendez et je mes fixations s pas bien réglées z est en_fait c’est m- + ma chaussure qu était
partie
Text Normalization: current languages
French: 347k words
Italian: 389k words
German: 383k words
Polish: 576k words
English: 121k words
Catalan: 93k words
Portuguese: 41k words
Spanish: 22k words
Japanese: 18k words
Mandarin Chinese: 110k words
Cantonese: 46k words
Korean: 33k words
Min nan: 1k syllables in pinyin
Naija: 5k words + English
The better lexicon, the better automatic text normalization.
Text Normalization: Adding a new language
add lexicons
add the num2letter module
Example:
Roxana Fung, Brigitte Bigi (2015).
Automatic word segmentation for spoken Cantonese.
In Oriental COCOSDA and Conference on Asian Spoken Language Research and Evaluation,
pp. 196–201.
Text Normalization: reference
Brigitte Bigi (2014).
A Multilingual Text Normalization Approach.
Human Language Technologies Challenges for Computer Science and Linguistics.
LNAI 8387, Springer, Heidelberg. ISBN: 978-3-319-14120-6. Pages 515-526.
Phonetization
Phonetization is also known as grapheme-phoneme conversion
Phonetization is the process of representing sounds with phonetic signs.
Phonetic transcription of texts is an indispensable component of text-to-speech (TTS) systems and is used in
acoustic modeling for automatic speech recognition (ASR) and other natural language processing applications.
Converting from written texts into actual sounds, for any language, cause several problems that have their
origins in the relative lack of correspondence between the spelling of the lexical items and their sound
contents.
Phonetization: SPPAS research approach
a generic approach:
consists in storing a maximum of phonological knowledge in a lexicon.
In this sense, this approach is language-independent.
the phonetization process is the equivalent of a sequence of dictionary look-ups.
Phonetization: dictionary
An important step is to build the pronunciation dictionary, where each word in the vocabulary is expanded
into its constituent phones, including pronunciation variants.
Phonetization of normalized speech transcription
SPPAS is proposing a language-independent algorithm to phonetize unknown words
given enough examples (in the dictionary) it should be possible to predict the pronunciation of
unseen words purely by analogy.
The better dictionary, the better automatic phonetization.
Phonetization: reference
Brigitte Bigi (2016).
A phonetization approach for the forced-alignment task in SPPAS.
Human Language Technologies Challenges for Computer Science and Linguistics.
LNAI 9561, Springer, Heidelberg.
Alignment
Alignment is also called phonetic segmentation
The alignment problem consists in a time-matching between a given speech unit along with a phonetic
representation of the unit.
Many freely available tool boxes, i.e., Speech Recognition Engines that can perform Speech Segmentation
HTK - Hidden Markov Model Toolkit
CMU Sphinx
Open Source Large Vocabulary CSR Engine Julius
…
Alignment
Algorithms are language independent
An acoustic model must be created
training procedure
based on examples
“more data is good data”… or not!
Training a model:
requires audio files
requires orthographic transcription
requires IPUs/utterrances segmentation
Alignment: current languages
French
English (from voxforge.org)
Italian
Spanish
German
Catalan
Polish
Mandarin Chinese
Min nan
Naija
Japanese (from Julius software)
Cantonese (from University of Hong Kong)
Korean (under construction)
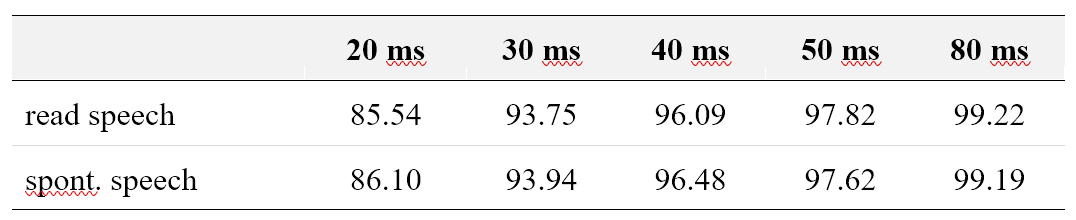
Alignment: results of French
Unit Boundary Position Accuracy (UBPA): what percentage of the automatic-alignment boundaries are within a
given time threshold of the manually aligned boundaries.
UBPA of French on read and spontaneous speechManual vs automatic durations of vowels on conversational speech
Alignment: references
Brigitte Bigi (2012).
The SPPAS participation to the Forced-Alignment task of Evalita 2011.
B. Magnini et al. (Eds.): EVALITA 2012, LNAI 7689, pp. 312-321. Springer, Heidelberg.
Brigitte Bigi (2014).
The SPPAS participation to Evalita 2014.
In Proceedings of the First Italian Conference on Computational Linguistics CLiC-it 2014
and the Fourth International Workshop EVALITA 2014, Pisa, Italy.
Brigitte Bigi (2014).
Automatic Speech Segmentation of French: Corpus Adaptation.
In 2nd Asian Pacific Corpus Linguistics Conference, pp. 32, Hong Kong.
Speech segmentation: main reference
Brigitte Bigi, Christine Meunier (2018).
Automatic speech segmentation of spontaneous speech.
Revista de Estudos da Linguagem.
International Thematic Issue: Speech Segmentation.
Editors: Tommaso Raso, Heliana Mello, Plinio Barbosa,
e - ISSN 2237-2083
Brigitte Bigi, Christine Meunier, Irina Nesterenko and Roxane Bertrand (2010).
Automatic detection of syllable boundaries in spontaneous speech.
Language Resource and Evaluation Conference, pages 3285-3292, La Valetta, Malte.
Syllabification of Italian: reference
Brigitte Bigi and Caterina Petrone (2014).
A generic tool for the automatic syllabification of Italian.
In Proceedings of the First Italian Conference on Computational Linguistics CLiC-it 2014 and
of the Fourth International Workshop EVALITA 2014, pp. 73–77, Pisa, Italy.
Syllabification of Polish: reference
Brigitte Bigi and Katarzyna Klessa (2015).
Automatic Syllabification of Polish.
In 7th Language and Technology Conference: Human Language Technologies as a Challenge for
Computer Science and Linguistics, pp. 262–266, Poznan, Poland.
Other-repetition is a device involving the reproduction by a speaker of what another speaker has just
said.
Other-repetition has been identified as an important mechanism in face-to-face conversation through their
discursive or communicative functions.
Example:
Extract of Corpus of Interactional Data
AB: ils voulaient qu'on fasse un feu d'artifice en fait dans un voy- un foyer un foyer catho
un foyer de bonnes soeurs
CM: un feu d'artifice
AB: ah ouais
CM: dans un foyer de bonnes soeurs
CM: @
Repetitions
No system already existing
Our solution is based only on lexical criteria
observable cues: time-aligned tokens converted to lemmas (if any).
The system was used to propose a lexical characterization of OR: various statistics was estimated on the
detected OR.
Other-Repetitions: result
AB:
CM:
Repetitions: reference
Brigitte Bigi, Roxane Bertrand, Mathilde Guardiola (2014).
Automatic Detection of Other-Repetition Occurrences: Application to French Conversational Speech.
In Proceedings of the Ninth International Conference on Language Resources and Evaluation,
pp. 836-842, Reykjavik, Iceland.