CLeLfPC
Corpus de Lecture en Langue française Parlée Complétée
Created in 2021 by Brigitte Bigi and Maryvonne Zimmermann
The corpus is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. It can be used for any research or teaching purpose.
We asked the 23 volunteer participants to read aloud and to cue one topic among the 10 we prepared. Two participants accepted to read 2 different topics. Each topic was made of 4 sessions; the sessions were recorded separately for the participant to have a short break:
- 32 isolated “CV” syllables;
- 32 isolated words or phrases;
- isolated sentences;
- a text divided into 4-7 parts.
The corpus is made of 4 hours of high quality audio-video recordings.
Corpus Grenelle II and its annotations
Created in 2010-2011 by Brigitte Bigi, Cristel Portes, Agnès Steuckardt, Marion Tellier.
- Video downloaded from a FTP server (after authorization), a flv file with poor quality
- Audio extracted from the video
- A large amount of time-aligned annotations
- Freely available: SLDR 000729
Demo
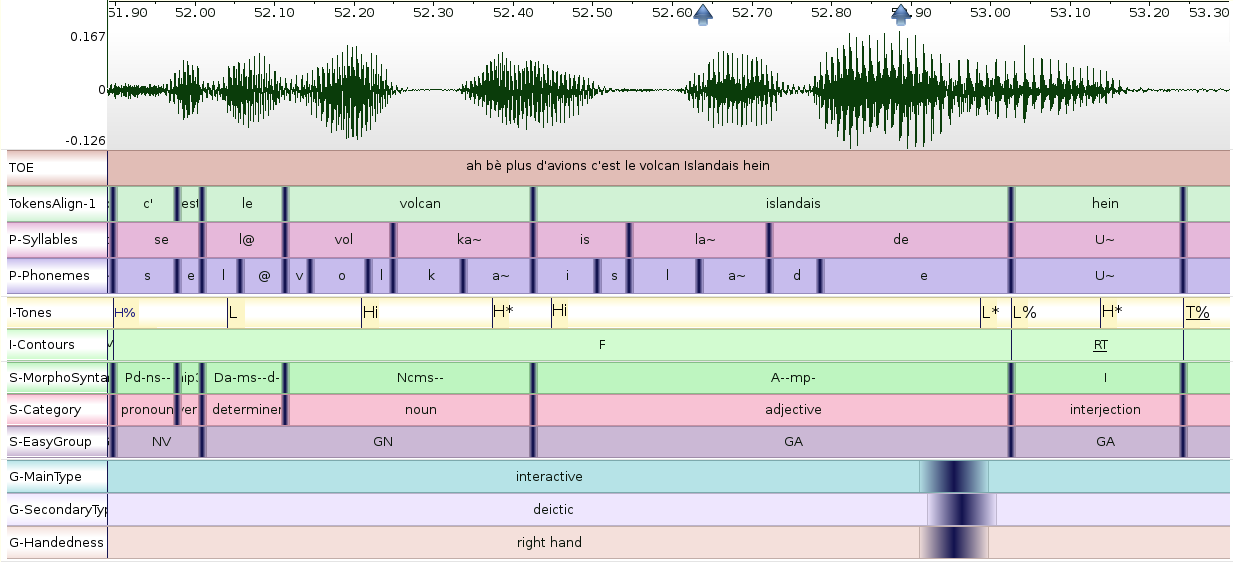
Grenelle II annotations
- Enriched orthographic transcription (manual), time-aligned at the utterance level (automatic)
- Time-aligned phonemes, tokens and events (automatic)
- Time-aligned syllables (automatic)
- Prosodic contours and intonation (manual)
- Morpho-syntax time-aligned at the token level (automatic)
- Hand gestures
- Self-repetitions (semi-automatic)
- Interruptions (manual)
Publications
B. Bigi, C. Portes, A. Steuckardt, M. Tellier
Multimodal Annotations and Categorization for Political Debates,
ICMI Workshop on Multimodal Corpora for Machine learning (ICMI-MMC), Alicante (Espagne), 2011
B. Bigi, C. Portes, A. Steuckardt, M. Tellier
A Multimodal Study of Answers to Disruptions.,
Journal on Multimodal User Interfaces, Volume 7, Issue 1, Pages 55-66, Springer (Publisher). ISSN 1783-7677. DOI 10.1007/s12193-012-0110-zi, 2012
Corpus MARC-Fr
Created in 2011 by Brigitte Bigi and Pauline Péri
Description :
Corpus in French manually phonetized and time-aligned at the phoneme level. Its duration is 7 minutes (5400 phones), and made of 3 extracts of the following corpora: CID, AixOx and Grenelle.
Download
- the audio files in wav format
- the orthographic transcription, time-aligned in IPUs, in TextGrid format
- the manually time-aligned phonemes in TextGrid and ctm formats
Freely available for downloads:SLDR 000786
Publication
B. Bigi, P. Péri, R. Bertrand
Orthographic Transcription: Which Enrichment is required for Phonetization?,
Language Resources and Evaluation Conference, Istanbul (Turkey), pages 1756-1763, ISBN 978-2-9517408-7-7. 2012
Corpus AixOx
Read corpus created between 2010 and 2012 by Sophie Herment, Anastassia Loukina, Anne Tortel, Daniel Hirst, Brigitte Bigi
Description
40 paragraphes of about 1 minute in French and English, from EUROM 1 corpus. French texts are read by French native speakers (mainly from Aix-en-Provence) and by English native speakers (from Oxford). English texts are read by native English speakers and by French native speakers.
Download
- the audio files in wav format
- the orthographic transcription, time-aligned in IPUs, in TextGrid format
Freely available for downloads:SLDR 000784
Publication
S. Herment, A. Loukina, A. Tortel, D. Hirst, B. Bigi
AixOx, a multi-layered learners corpus: automatic annotation
Proceedings of international conference on corpus linguistics, Jaèn (Spain), March 2012.
CID - Corpus of Conversational Data
- Face-to-face conversations in French
- Created by Roxane Bertrand and Béatrice Priego-Valverde
- 8 semi-guided dialogs (110,000 words)
- Recorded in 2003 and 2005
- A very large amount of time-aligned annotations
- Available at:
Demo
CID - Some of the annotations
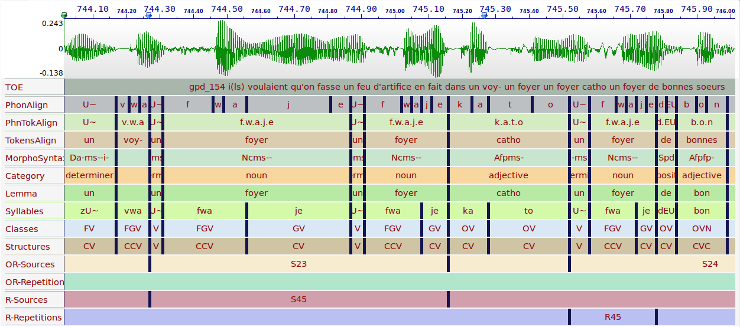
Enriched orthographic transcription (manual), time-aligned at the IPU level (automatic)
Time-aligned phonemes and tokens and events like noises, laughter (automatic) and time-aligned syllables (automatic)
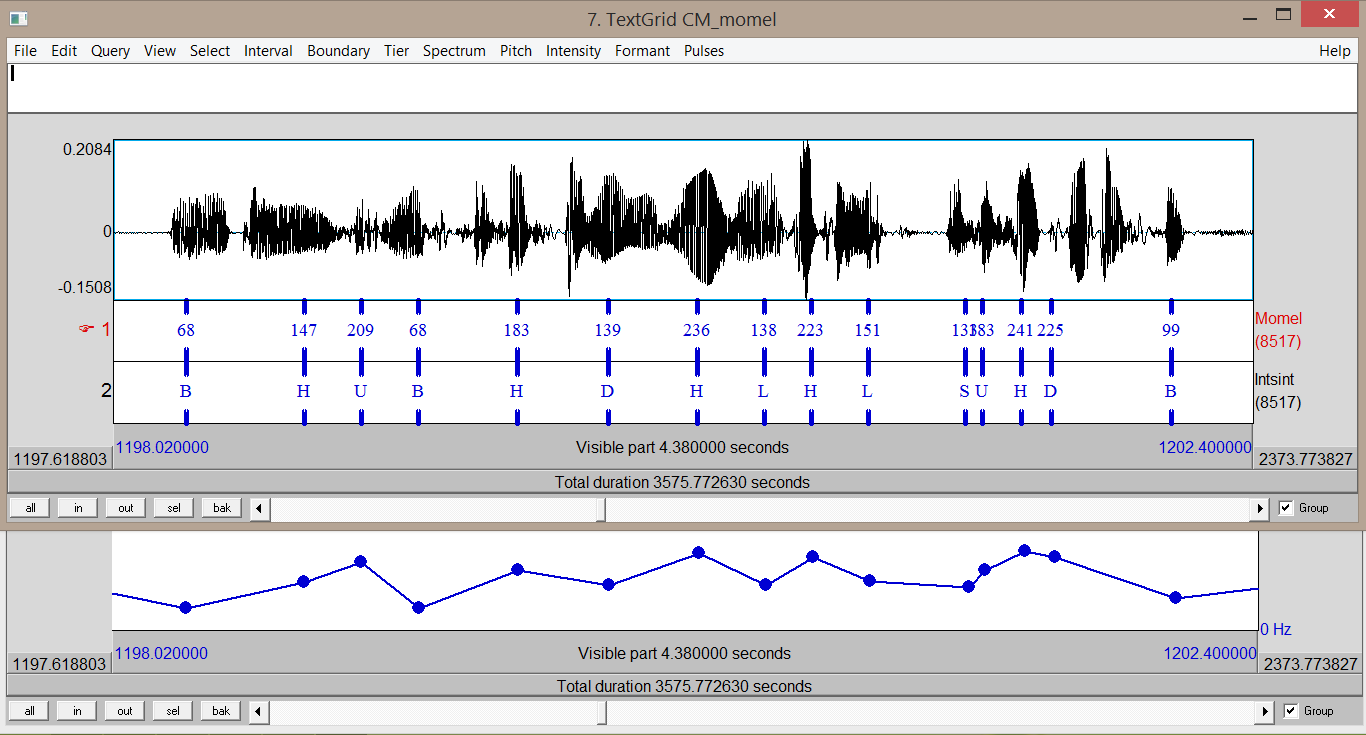
Prosodic contours (manual), Momel - Modelization of melody (automatic) and INternational Transcription System for INTonation (automatic)
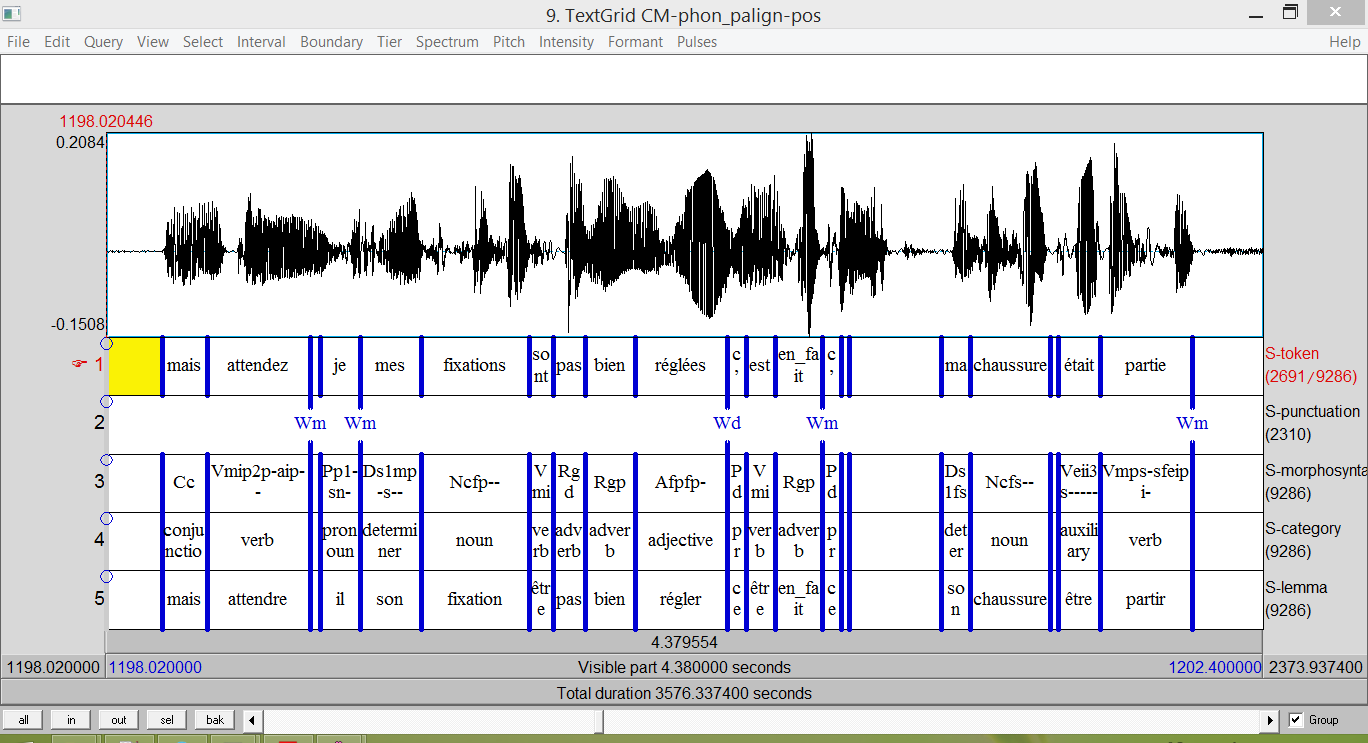
Morpho-syntax and syntax time-aligned at the token level (automatic) and time-aligned lemmas (automatic);
Dysfluencies (manual), Discourse and interaction (manual), Other- and Self- Repetitions (semi-automatic)

Publication
P. Blache, R. Bertrand, B. Bigi, E. Bruno, E. Cela, R. Espesser,
G. Ferré, M. Guardiola, D. Hirst, E.-P. Magro, J.-C. Martin,
C. Meunier, M.-A. Morel, E. Murisasco, I Nesterenko, P. Nocera,
B. Pallaud, L. Prévot, B. Priego-Valverde, J. Seinturier,
N. Tan, M. Tellier, S. Rauzy
Multimodal Annotation of Conversational Data,
The Fourth Linguistic Annotation Workshop, ACL 2010, pages 186-191, Uppsala, Suède, 2010.